목차
2023학년도 2학기 충남대학교 양희철 교수님의 기계학습 수업 정리자료입니다.
🌱 Curse of dimensionality
차원이 높으면 높을수록, 즉 feature가 많을수록 데이터가 더 많이 필요하다. 즉 단순히 차원이 높을수록 좋은 것이 아니다. 때문에 불필요한 feature들은 줄여야한다.
이상적으로는 feature의 수가 많을수록, feature들이 독립적이라는 가정 하에 성능이 좋아진다. 하지만 실제 세계에서는 모든 feature들이 서로 독립적이라는 보장이 없고, feature들 중 noise가 있을 수 있다.
저차원에 비해 고차원으로 표현되면 더 많은 데이터가 필요하고, 문제와 관련없거나 큰 영향을 끼치지 않는 feature가 존재할 수도 있으며, 과하게 feature를 반영하면 overfitting이 발생하거나 연산량이 많아질 수 있다.
예를 들어 overfitting 문제를 살펴보자. 1차원에서는 Goal/Game feature만 가지고서도 좋은 축구선수를 가려낼 수 있는데, Hair Color와 같은 불필요한 feature가 추가된 2차원에서는 분류 기준을 세우는데 overfitting이 될 수 있다.

때문에 가능한 한 작은 크기의 feature subset을 구해서 성능을 좋게 만드는 것이 목표이다.
📁 Dimensionality reduction
차원을 축소하는 방법에는 Feature selection과 Feature extraction으로 크게 두가지가 있다.
1. Feature Selection
feature들 중 몇 가지를 선택해서 고르는 방식이다. filter apprach와 wrapper approach의 두 가지 접근방법이 있다.
1) Filter approach
차원을 먼저 축소시킨 후 Learning Method로 모델을 학습시킨다.
2) Wrapper approach
선택된 subset에 대해 Learning Method가 feedback을 전달하는 과정을 반복한다. 성능이 더 좋지만 계산량이 늘어난다.
Feature를 선택하는 알고리즘을 살펴보자.
🌱 Exhaustive search
모든 가능한 feature subset을 구해서 모두 실행해보는 방법이다. 만약 n개의 feature가 있다면 가능한 subset의 조합 개수는 2^n-1개이다.
성능이 가장 뛰어나지만 계산해야하는 경우의 수가 많기 때문에, 이상적인 방법이지만 실제로 사용하기 어렵다. 때문에 보다 Heuristic한 방법인 Forward search, Backward elimination, Stepwise search 방법을 사용한다.
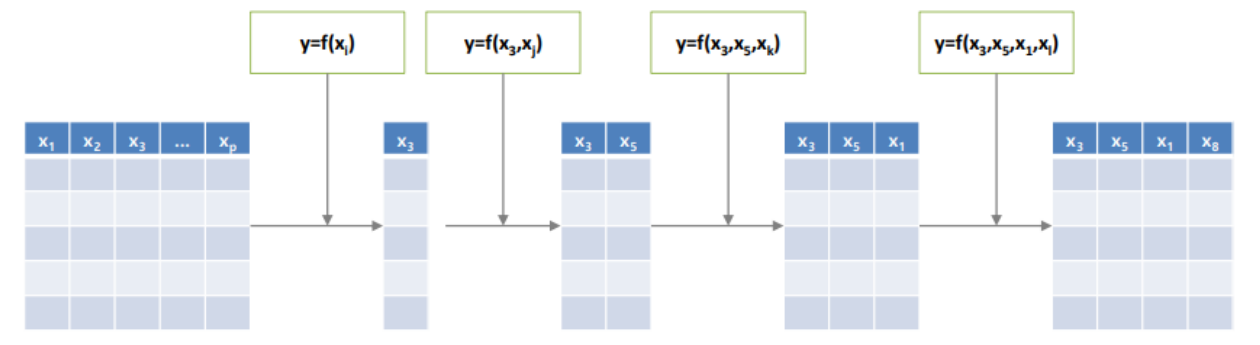
🌱 Forward Search
feature 하나씩 더해가면서 모델을 학습 후 성능을 측정한다.
🌱 Backwrd elimination
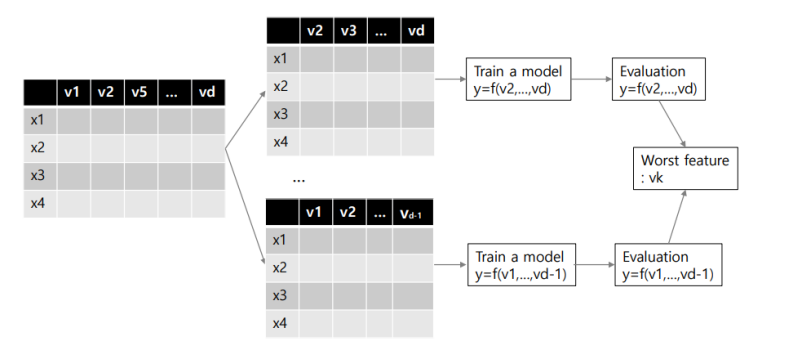
feature를 하나씩 빼보면서 모델을 학습 후 성능을 측정한다.
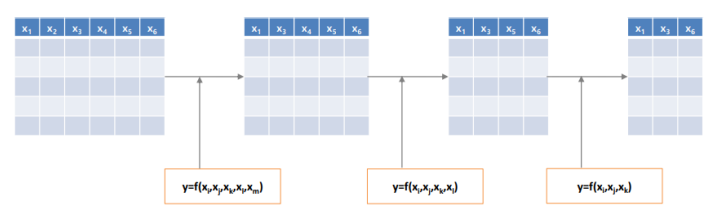
🌱 Stepwise search
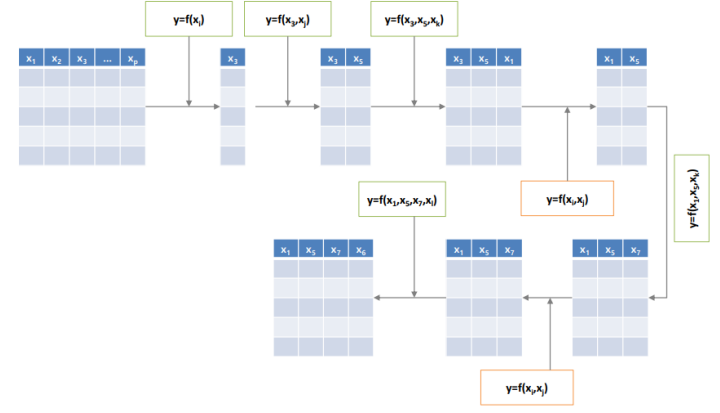
Forward search와 backward elimination을 합친 방법이다. 처음에는 feature를 추가해가다가 어떠한 기준에 마주치거나, feature를 늘리는 이득에 비해 손해가 크다면 feature를 제거하는 방식으로 진행한다.
이때 그 기준에는 Akaike information criterion, Bayesian information criterion 등이 많이 사용된다.
(1) Akaike information criterion (AIC)
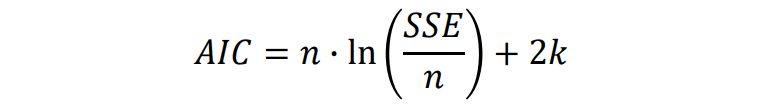
error와 feature의 개수를 함께 고려하는 방식이다.
(2) Bayesian information criterion (BIC)
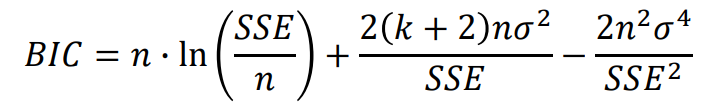
n : 데이터 개수 / k : feature의 개수
🌱 Genetic algorithm (GA, 유전 알고리즘) based search
Meta-heuristic한 방법 중 하나로, Exhaustive search와 heuristic한 방법을 나타내는 local search를 합친 방법이다. exhaustive search는 연산량이 많지만 global optimum을 찾을 수 있고, local search는 전체 범위의 일부만 보기 때문에 local optimum을 구하지만 효율적이다. 이를 잘 결합한 방법이 GA based search이다.
즉 exhaustive search보다는 효율적이고, local search보다는 나은 solution을 구한다.
모든 featuer case들을 탐색하지는 않지만, local optimum에 빠지지 않도록 함으로써 이론적으로는 global optimum을 얻을 수 있고, 실제로는 그 가까운 값을 얻을 수 있다.
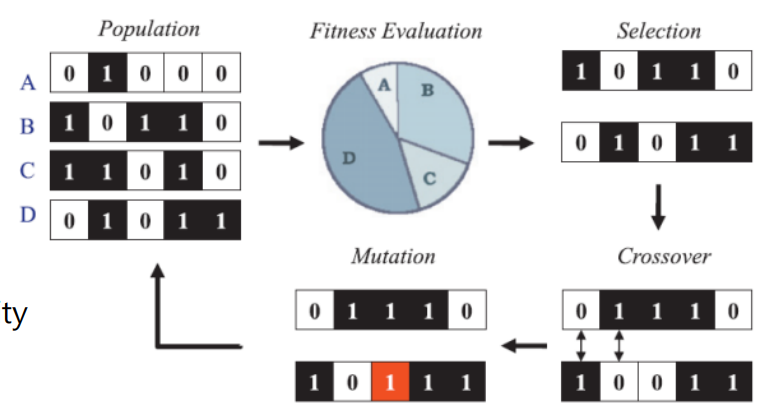
- Selection : 부모 중 두 개를 선택한다.
- Cross-over : 정보를 섞는다.
- Mutation : 변종을 생성한다.
전체적인 프로세스는 다음과 같다.
1) Chromosome encoding

feature 개수만큼 gene을 가진 ghromosome을 만들고 그 값을 1 또는 0으로 binary encoding한다.
2) Population setting
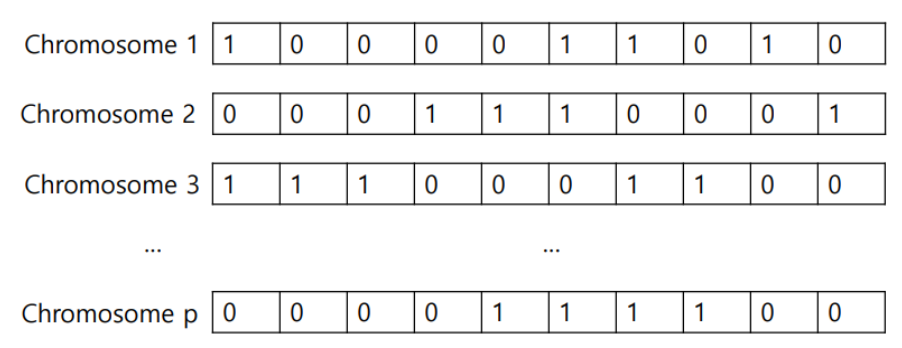
p개의 chromosome을 만든다.
3) Fitness evaluation

위에서 설명한 AIC, BIC 등은 Fitness function이라고 불리는데, 각 chromosome을 이용해 모델을 학습시킨 뒤 fitness function을 적용하는 과정을 거친다.
4) Selection
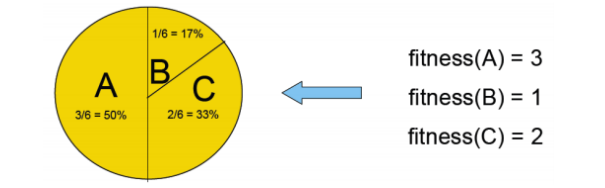
각 finess 값을 고려해서 부모로 선택될 chromosome을 선택한다. 이때 선택하는 방법은 두 가지가 있다.
(1) Deterministic selection : 상위 n%의 fitness value를 선택한다.
(2) Probabilistic selection : 중요한 feature set에 weight를 부여한 후 랜덤하게 선택하여 local optimum에서 벗어나도록 한다. 더 선호된다.
5) Cross-over
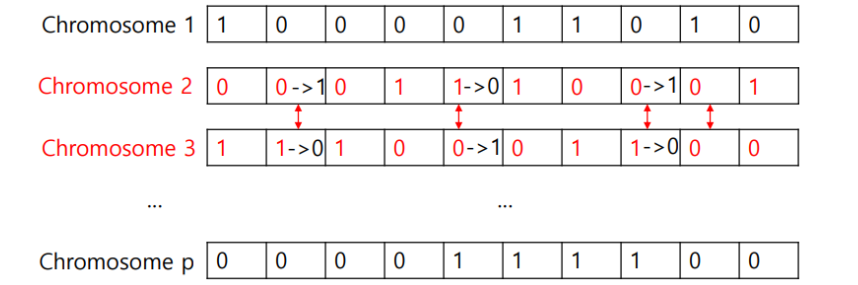
parents로부터 children을 생성한다. 이때 만드는 방법은 cross-over point에 해당하는 값을 서로 바꿔준다.
6) Mutation

새로 생성된 chromosome에서 낮은 확률로 일부 값을 바꿔준다. local optimum에 빠지지 않도록 하는 장치가 된다.
7) Create next generation
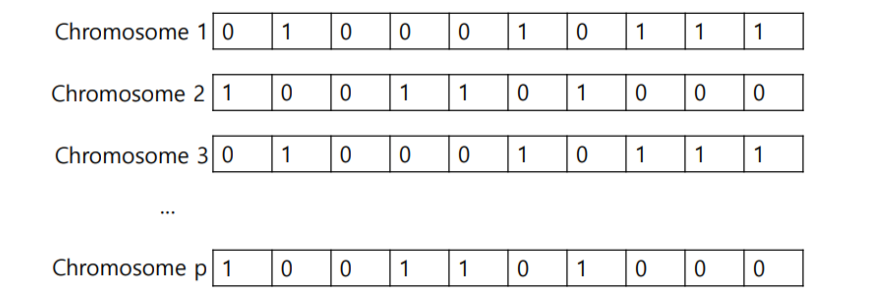
이렇게 새 feature set들이 생성이 된다.
위 과정에서 설정해야하는 hyper-parameter의 종류는 다음과 같다.
- 한 번의 반복에 해당하는 population의 chromosome의 개수
- 반복(generation) 횟수
- selection 메소드
- cross-over rate
- mutation rate
- termination criteria
hyper-parameter에 큰 영향을 받지는 않는다.
장단점은 다음과 같다.
- 이론적으로는 global optimum에 도달할 수 있지만, 무한번 반복할 수 없기 때문에 실제로는 근처에만 도달할 수 있다.
- global optimum에 가까울것이라고 추측은 하지만 실제로 평가할 수는 없다.
- 걸리는 시간 및 연산량이 크다.
2. Feature Extraction
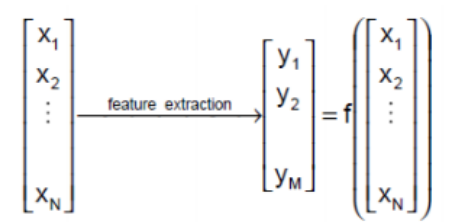
feature들 재조합해서 새 feature를 구하는 방식이다. 대표적인 알고리즘으로 Principal component analysis가 있다.
🌱 Principal component analysis (PCA)
원본 데이터의 variance(분산)를 최대한 포함하는 축인 principal component(주성분)을 찾아야한다.
variance가 커야 각 variable이 큰 의미를 가질 수 있으므로, variance가 클 수록 좋은 base라고 판단한다.
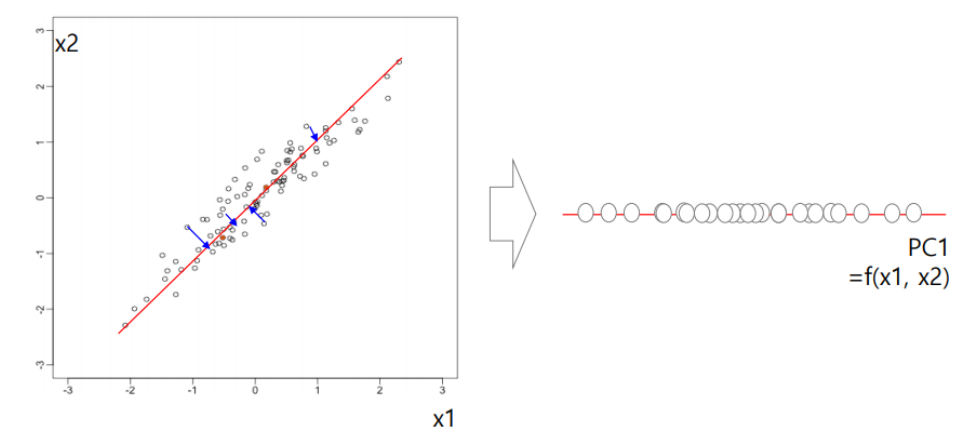
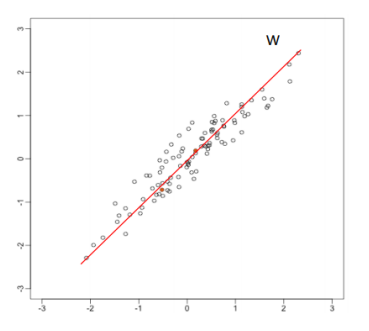
위와 같은 빨간색 선을 새 feature로 두고, 오른쪽과 같이 1차원으로 새로 매핑해보자. 기존의 x1, x2 축보다 variance가 크다.
이처럼 주 성분을 찾으면 feature를 extraction하는데 효과적이다.
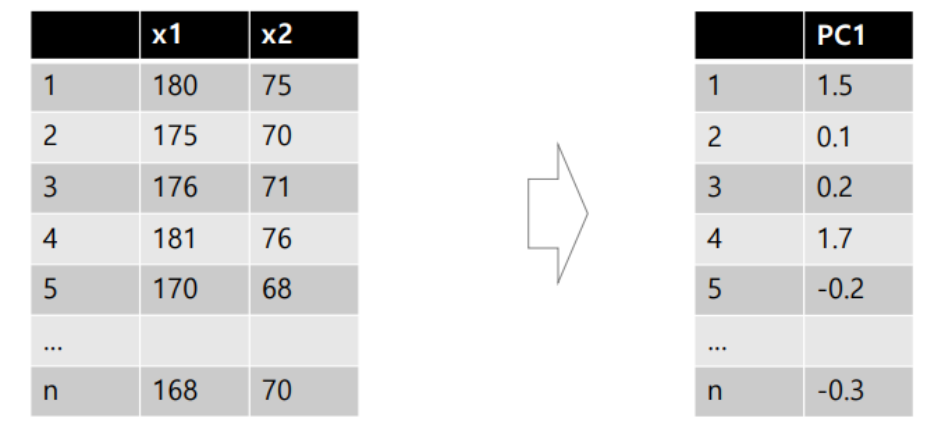
위와 같이 두 feature가 나눠 갖던 값을 하나의 PC1이라는 feature의 값으로 mapping해야한다. 이때 다음과 같은 계산 방법을 사용한다.
Covariance 및 Eigenvector와 Eigenvalue는 다음과 같이 구한다.
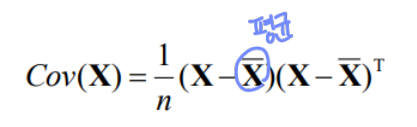
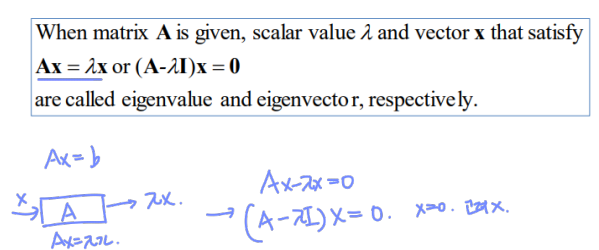
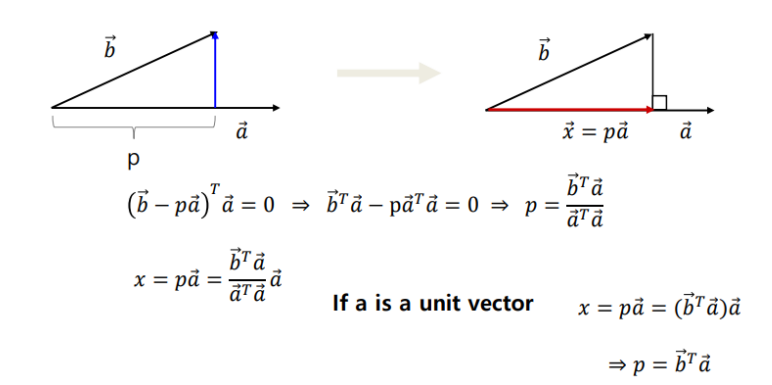
결국 데이터 x를 벡터 w에 매핑시켰을때 variance가 큰 w를 찾는 문제이다. X를의 평균을 0로 맞춘 상태일 때, X를 w에 매핑하는 과정은 다음과 같다.
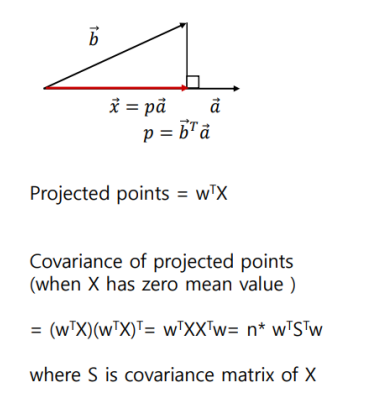
결국 w의 방향이 중요하므로, w는 1이라고 가정하고 어래와 같은 값의 최댓값을 구함으로써 variance를 키울 수 있다.

이를 정리하면 다음과 같다.
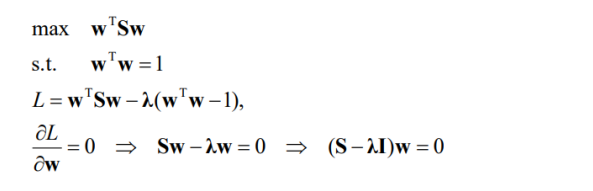
최종적으로 Eigenvector가 주성분이 된다.
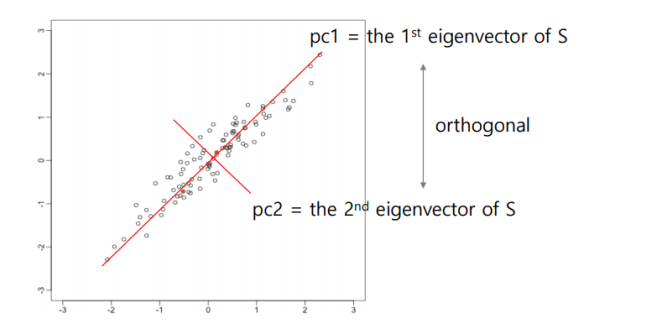
이후 하나의 feature를 더 찾고싶다면, 이전에 찾은 벡터와 orthogonal하게 찾아야한다.
이외에도 feature extraction 방법에는 Singular value decomposition(SVD), Kernel PCA, Autoencoder 등의 방법이 있다.



