2023학년도 2학기 충남대학교 양희철 교수님의 기계학습 수업 정리자료입니다.
🌱 Empirical risk minimization (ERM)
기존의 모델은 ERM의 영역. empirical : 실험적인. 실험을 통해 에러를 최소화하는 방법.
이때 empirical, 실험이란 training data를 사용한 학습을 일컫고, risk는 이 training data로 학습하는 과정에서 발생하는 training error를 뜻함.
ERM 방법은 training data에 대한 최적의 모델을 찾을 수 있기 때문에 overfitting이 발생할 수 있다는 단점이 있고, 이를 validation, cross-validation, regularization 등으로 해결할 수 있었다.

위 사진에서 solution 1, 2, 3의 risk는 모두 같다. 이럴때 어떤 solution 방향으로 업데이트를 진행해야할까?
실제 사람이 판단하기에는 solution 1이 적합하다. 현재 존재하는 데이터 분포와 유사한 추가 데이터들이 도입될 때, 리스크가 더 적을것이라고 예상되는 solution은 1번이기 때문이다. 이를 학습 과정에 적용하기 위해 Structural risk minimization 방법을 사용한다.
🌱 Structural risk minimization (SRM)
solution에 Margin을 도입한다. 이때 margin이란 solution과 가장 가까운 데이터들 사이의 거리를 말한다. 이 margin이 크면 클수록 더 좋은 모델이다.
solution 함수들이 위와 같은 형태라고 하자. 함수의 위 데이터들중 가장 가까운 데이터와의 거리를 1, 아래 데이터들중 가장 가까운 데이터와의 거리를 -1이라고 조정하면, 해당 데이터들과 decision surface 사이의 거리는 다음과 같이 계산할 수 있다.
우리는 margin이 최대가 되는 solution을 찾고 싶어 하므로, 위에서 계산한 거리값이 최대가 되도록 하면 된다. 또한 이를 계산해보면 오른쪽과 같은 값을 최소로 만드는 w를 찾는 것이 목표가 된다.
SRM의 대표적인 알고리즘으로 Support Vector Machine이 있다.
📁 Support Vector Machines (SVM)
SRM에서 설명한 방식에서, margin을 계산하는 decision surface와 가장 가까운 데이터를 support vector라고 부른다.
1. Support Vector Classifiers
🌙 Hard margin
hard margin이란 모든 트레이닝 데이터가 margin 밖에 있거나 걸쳐있으며, 모든 데이터를 100퍼센트 분류할 수 있는 경우에 수행하는 SVM이다. linear SVM에서 사용된다.
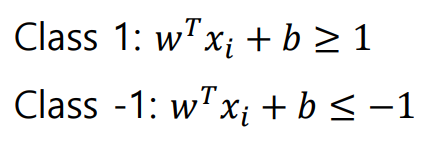
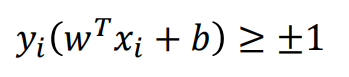
위에 위치한 데이터는 class 1, 아래 위치한 데이터들은 class -1이라고 가정하면 왼쪽 식과 같이 모든 데이터들과 decision surface 사이의 거리는 1보다 크거나 -1보다 작으며, 이를 하나의 공식으로 정리하면 오른쪽과 같다.
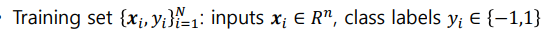
위와 같이 가정하자.
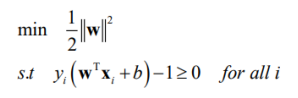
모든 training 데이터가 마진 밖에 혹은 걸쳐있도록 하는 margin의 최대값을 구하기 위해서, 위와 같은 값을 최소로 만드는 w를 찾아야한다.
Hard Margin의 경우 문제를 해결하는 방법으로 Quadratic Programming (QP)가 있다.
1) Primal Lagrangian formulation
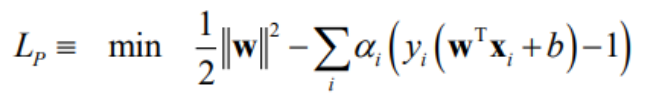
기존의 왼쪽 가정을 하나의 식으로 정리한 공식으로, Hard Margin SVM을 해결 할 때 위 L(p)를 최소로 만드는 w값을 찾아 해결할 수 있다.
2) Partial derivatives (KKT condition)
3) Dual problem
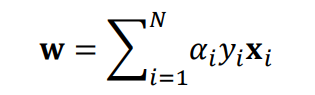
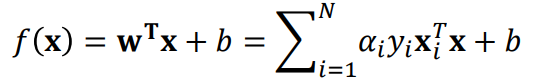
결론적으로 Hard margin SVM에서 w값은 위와 같으며, 이 w값을 기존 공식에 대입해서 오른쪽과 같은 해결 공식을 얻을 수 있다.
위 오른쪽 공식에 x,y 데이터를 넣어서 0보다 큰지 작은지를 구한 뒤 이진 분류를 수행하면 된다.
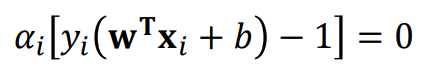
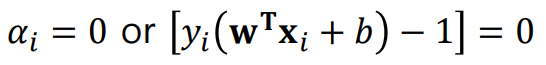
KKT condition에 따르면 왼쪽과 같은 경우의 x,y값을 갖는 데이터가 support vector이고, 그렇다면 오른쪽과 같이 계산할 수 있다.
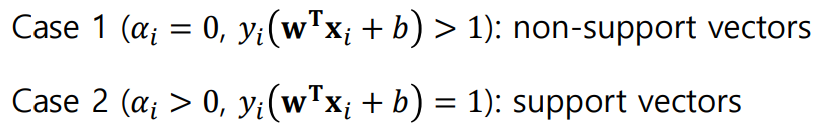
이때 support vector를 판단하는 방법은 위와 같다.

weight를 구할 때 모든 데이터를 볼 필요 없이 support vector만 고려하면 되므로, decision 함수를 위와 같이 support vector만 고려하는 방식으로 만들 수 있다.
🌙 Soft Margin SVM
하나의 decision 함수로 모든 데이터들을 구분하지 못할 때 사용하며, soft margin SVM에서는 마진 내에 데이터가 존재하기도 한다.
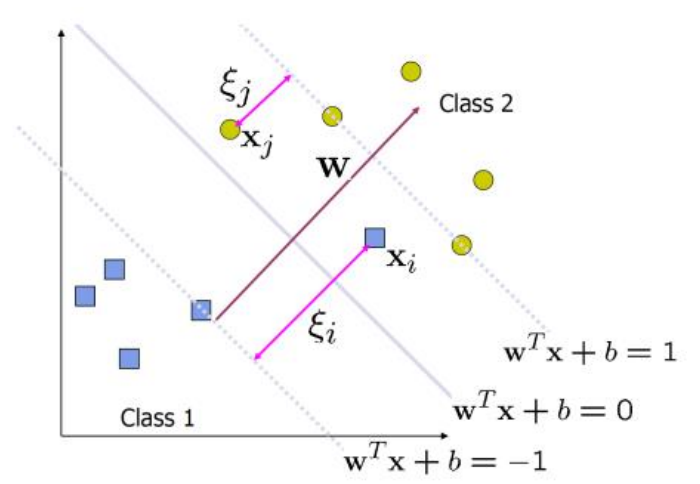
ξ(slack variable, panelty)란 각 데이터와 margin 함수 사이의 거리를 말한다. hard margin에서의 조건이 panelty를 적용하여 다음과 같이 바뀌어야한다.

즉 위쪽 클래스의 모든 데이터가 1보다 큰 게 아니라 1- ξ 보다 커야한다.

웨이트를 구하기 위한 공식도 위와 같이 변경되어야한다. 이때 C란 trade-off parameter를 말한다.
이를 정리하면 다음과 같다.
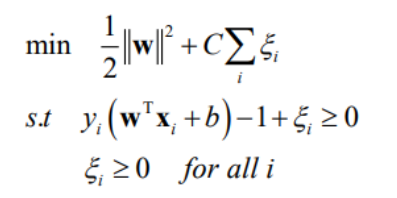
soft margin SVM 문제를 Primary Lagrangian fomulation 및 Partial derivatives (KKT condition)으로 해결하면 다음과 같다.
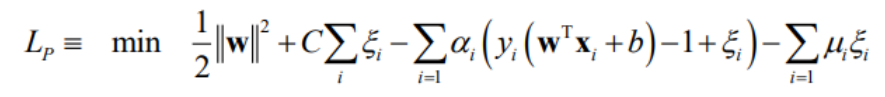
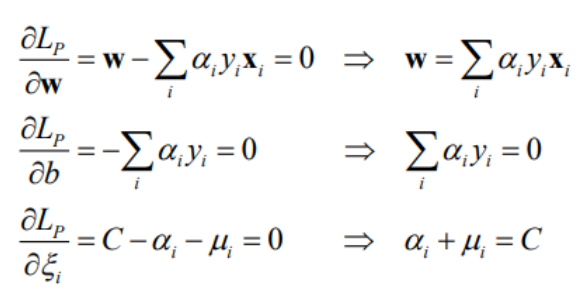
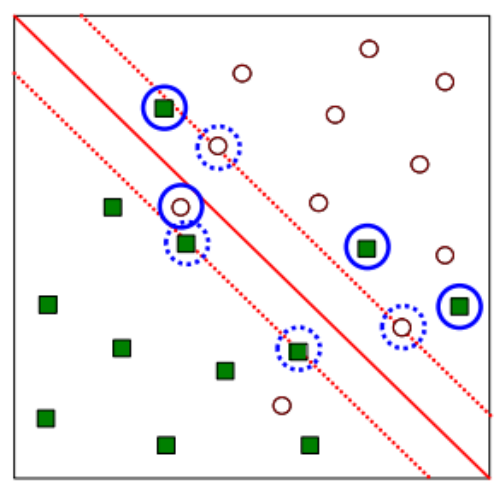

이때 margin에 걸친 support vector를 unbounded SV, margin 내에 존재하는 support vector를 bounded SV라고 한다.
sort margin은 여전히 linear해서 한계가 있다.
🌙 Nonlinear SVM
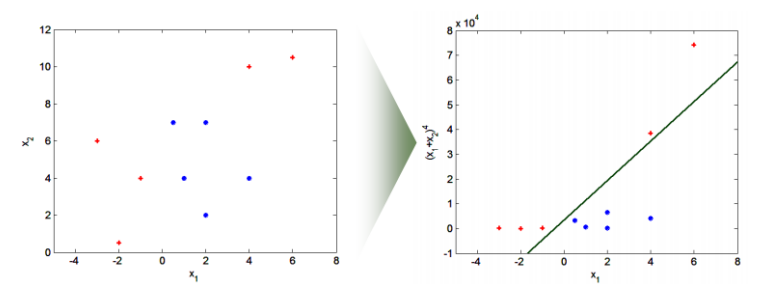
낮은 차원에서 linear하게 분류되지 않는 경우, 차원을 높이면 linear하게 분류할 수 있기도 한다.
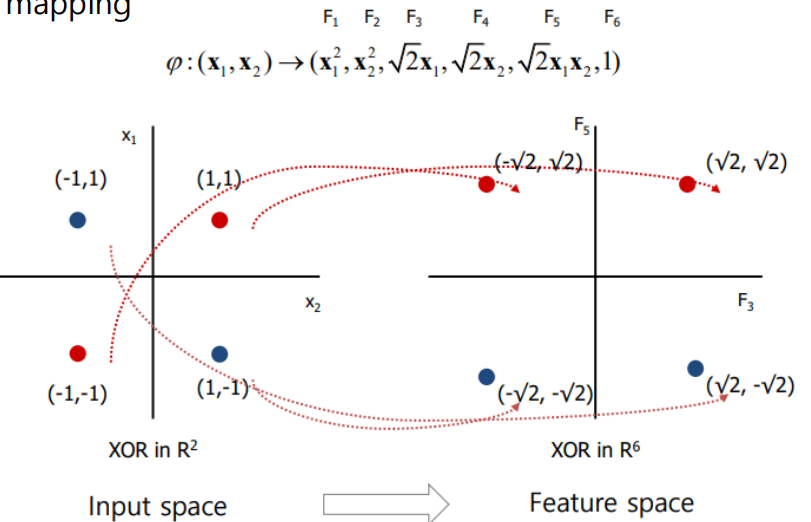
예를 들어 XOR 연산의 경우 기존에는 linear하게 분류할 수 없는데, 이를 약 6차원으로 표현하면 linear한 분류가 가능하다.
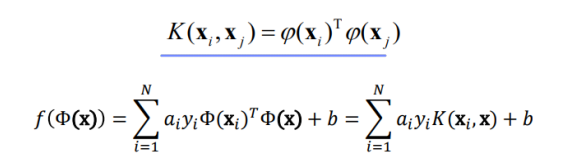
자주 사용되는 kernel function은 다음과 같다.

2. Support Vector Regression
𝜀-insensitive tube를 도입해서 soft margin 방법으로 계산할 수 있다.
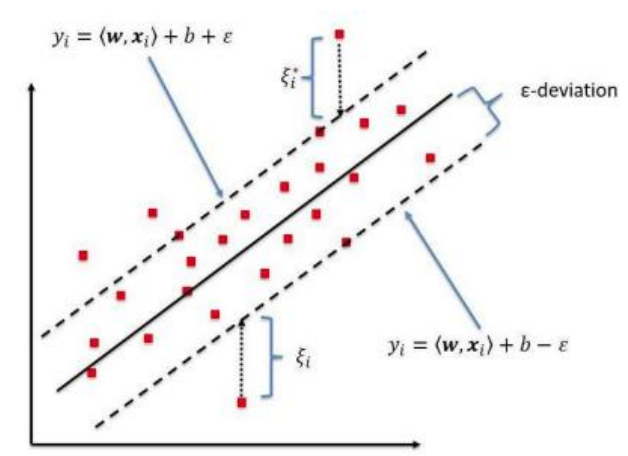

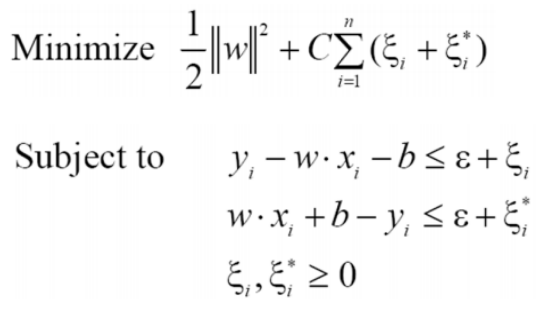
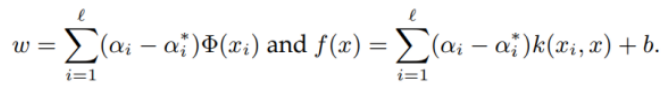
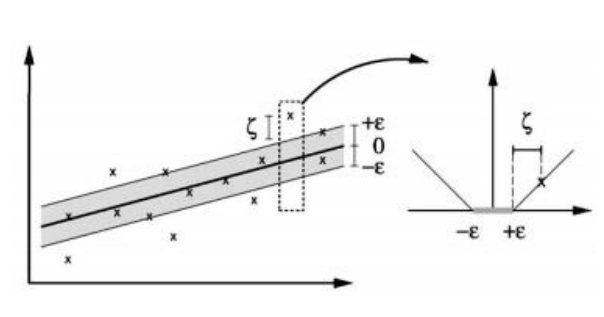
𝜀값이 크면 underfitting, 작으면 overfitting이 될 수 있다.



