2023학년도 2학기 충남대학교 양희철 교수님의 기계학습 수업 정리자료입니다.
📁 Deep Neural networks

Neural Network 방식에서 히든 레이어를 많이 둔 방식을 말하며, 사용하는 이유 다음과 같다.
- 더 복잡한 관계를 표현하기 위해 더 높은 capacity를 필요로 하기 때문이다.
- Universal approximation theorem이 nonlinear하게 복잡한 관계를 표현해주지만, 더 효율성을 추구하기 위해 사용한다.
- generalization 효과가 더 뛰어나다.
하지만 layer를 여러 층 쌓을때의 문제점은 다음과 같다.
1. Vanishing (or exploding) gradient
각각의 weight에 대한 편미분을 계산하다보면, 수많은 gradient를 계속 곱해주게 된다. 그러다보면 초기의 weight들은 결국 gradient가 0에 가까워지게 되므로 앞부분의 weight에 대한 학습이 제대로 되지 않는 문제가 발생한다.
이러한 문제는 hidden 노드의 activation function에 sigmoid가 아닌 ReLU function을 사용함으로써 해결할 수 있다.
sigmoid 함수는 기울기가 0에 가까운 부분이 너무 많고, 가장 큰 기울기도 약 0.24정도이기 때문에, 이 함수를 사용한다는 것은 0.24보다 작은 값을 계속 곱해준다는 것이다. 즉 곱하면 곱할수록 gradient가 작아지고, vanishing 문제가 발생한다.
ReLU 함수는 음수일땐 기울기가 0이고 양수일땐 1이기 때문에, 값이 양수일 경우 여러번 곱해도 gradient가 작아지지 않는다.
2. Overfitting
한 층에 여러개의 노드를 갖는것보다는 나은 방법이지만, 층이 여러개 쌓이고 노드가 여러개 생기게 되면 overfitting 문제가 발생할 수 있다. 이 문제는 regularization 기법으로 해결할 수 있다.
학습과정에서 일반적으로 특정 노드 사이의 연결을 끊어주는 drop-out 방법이 사용된다. 예를 들어 drop-out rate가 0.25인 경우, 노드 4개 중 하나의 연결을 끊는 식이다. 해당 방법을 사용하면 구조에 변형을 가질 수 있기 때문에 Ensemble method의 이점을 얻을 수 있다.
혹은 data augmentation 방법을 사용하여, 하나의 데이터를 여러가지 형태로 변형하여 사용할 수도 있다. 규제 및 일반화 성능을 얻을 수 있으며, 보통 이미지를 처리할때 많이 사용된다.
이외에도 parameter sharing, sparse connection 방법이 있다.
3. High capacity
weight를 업데이트하는 최적화 과정이 너무 오래걸리고 구조가 복잡해서 높은 capacity를 가진다. 이는 Stochastic Gradient descent(SGD) 방법으로 해결할 수 있다.
앞서 설명한 업데이트 과정은, 만약 데이터가 100개 있다고 가정할 때 첫번째 데이터를 넣어 예측값을 계산하고, loss를 계산한 후 weight 업데이트를 반복하는데, 실제로는 weight를 업데이트할 때 그 방향을 정해주어야한다. 이때 모든 경우의 수를 확인하고 업데이트하는 방식이 정확하므로, 100개의 loss를 모두 계산한 후 loss들의 평균에 대해 weight를 업데이트하는 Gradient descent 방식을 사용하도록 한다.
하지만 위 방법은 한 번 업데이트할 때 시간이 너무 오래걸리므로, 업데이트할 때 데이터를 한 개만 보고 업데이트하는 SGD 방식을 사요한다. 정확도는 비교적 떨어지지만 연산량이 줄어 더 빨라진다. 이때 데이터를 몇개 볼지 정해주는 방식은 mini-batch GD라고 하는데, 이를 일반적으로 SGD라고 말하기도 한다. mini-batch의 수가 1개인 mini-batch GD가 곧 SGD인것이다.
혹은 adaptive learning rate를 사용하여 해결할 수 있다. learning rate를 학습과정에서 계속 조절하는 방법으로, 각 step의 크기를 조절한다.
세번재로 momentum 방법은 관성이라는 뜻으로, 각 step의 결과값이 최적의 값으로 계속 향하는 것이 아닌 들쭉날쭉한 성격을 가지고 있다보니 이를 이전에 갔던 방향으로 가려는 관성이 있다고 표현하고, 해당 관성을 함께 더해서 다음 step을 정하는 방식으로 step의 방향을 조절한다.
adam이란 adaptive learning rate와 momentum방법을 함께 사용하는 것으로, 가장 일반적으로 사용되는 방법이다.
🌱 Deep Feedforward Networks
input과 output 사이의 관계, 함수를 최적의 함수를 근사하는게 최종 목표.
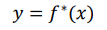
이런 최적의 함수가 잇다고하자. 우리는 얘를 모방하고자 하는거.
파라미터간의 출력값을 내도록.
#######뭐ㅗ라는거야###########
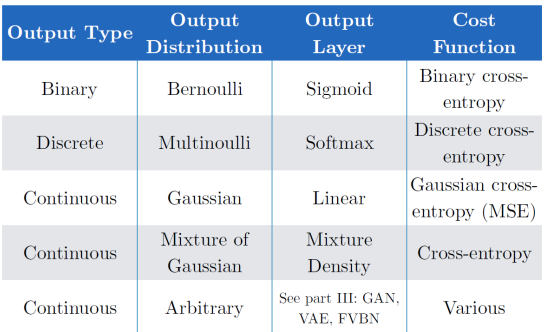
출력하고자 하는 형태나 학습하고자 하는 데이터 등에 따라 위와 같이 cost function을 결정할 수 있다.
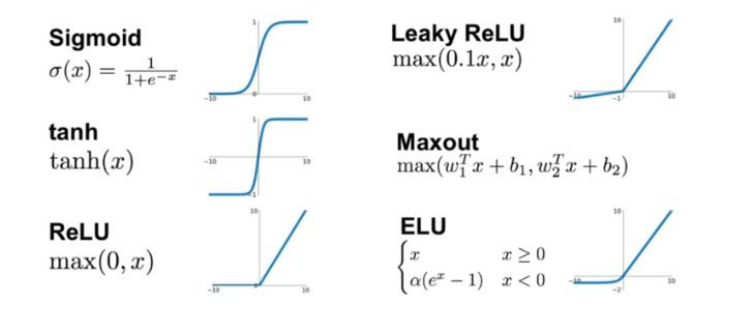
많은 activation function들 중 일반적으로 ReLU 방식이 가장 우수하다. 계산이 쉽고 미분값, 즉 기울기값이 전체적으로 크다는 장점이 있지만, 음수부분에서 activation function의 출력값이 0이 된다는 단점이 있기 때문에 backpropagation 과정에서 weight 업데이트가 제대로 이루어지지 않을 수도 있다. 하지만 해당 문제는 노드 및 레이어의 수가 많으면 큰 문제가 되지 않기 때문에 여전히 많이 사용되고 있다.
보통 ReLU 함수는 y=0과 y=x 함수 두개가 합쳐진 모습이므로 max(0, x)라고 표현한다. 만약 형태를 바꿔서 y=x랑 y=0.1x의 합으로 나타내고자 할때, 이를 generalized ReLU라고 부른다. 또한 0.1 자리를 알파로 두고 여기를 학습하자고 하는 방식을 Parameter ReLU라고 부른다.
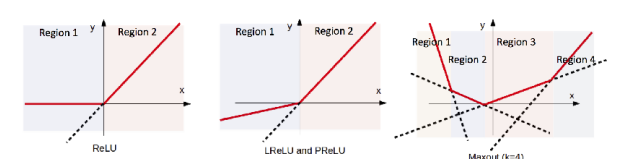
요새 ReLU, LReLU를 많이 쓰는 이유가 장점이 너무 좋아서. 연산량이 적음 (절대적인 연산량이 작은건아니지만)
📁 Convolutional Neural Networks (CNN)
CNN이란 1998년 LeCun에 의해 제안된 모델로, convolution을 연산에 활용한다.
이미지 처리에 특화된 모델이며, 보통 시간의 순서를 표현할 때는 1차원, 이미지를 표현할때는 픽셀을 표현할 수 있는 2차원을 사용한다.
이미지 처리에 특화된 모델. 컨볼루션을 연산에 활용.
이미지에서는 각 feature가 픽셀의 값. h * w * d. input의 크기가 엄청 커짐. 얘를 어떻게 효과적으로 처리할 수 있을까 ?
sparse connection. fully-connected network
필터의 개수는 = (i-1) 채널의 수 * i 채널의 수
필터 값의 개수 = (i-1) 채널의 수 * i 채널의 수 * 가로 * 세로
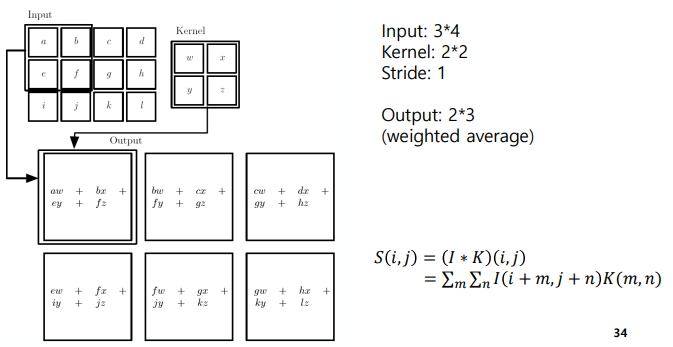
일반적으로 convolution operation은 위와 같이 진행된다.
🌱 CNN's Achievement
1. LeNet (1998)
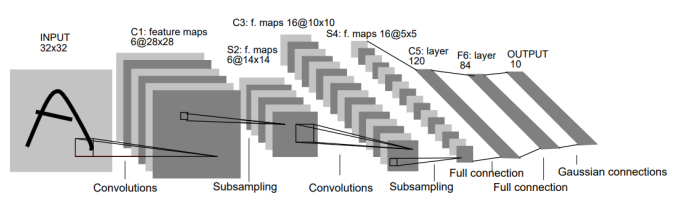
CNN이 처음 제안되었을때의 구조이다. convolution과 pooling을 반복하고, 원하는 형태가 될때까지 layer를 취하는 방법으로 이런 방법은 지금까지 사용되고 있다.
2. AlexNet (2012)
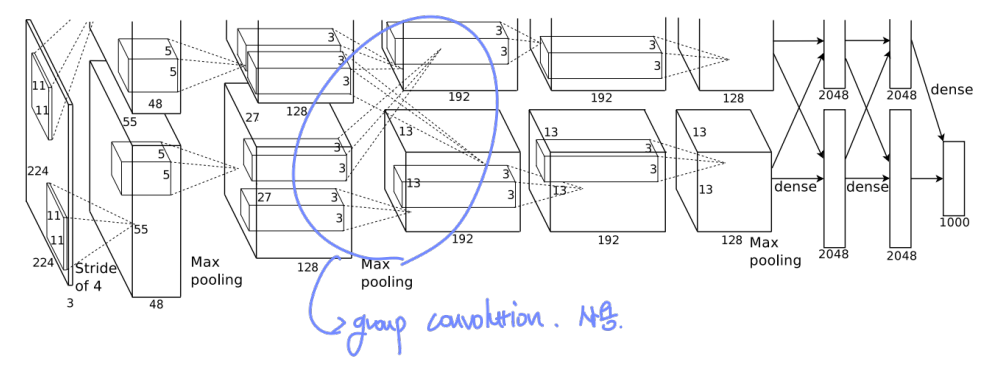
본격적으로 주목을 받기 시작했다. group convolution을 사용하고 있음을 볼 수 있다.
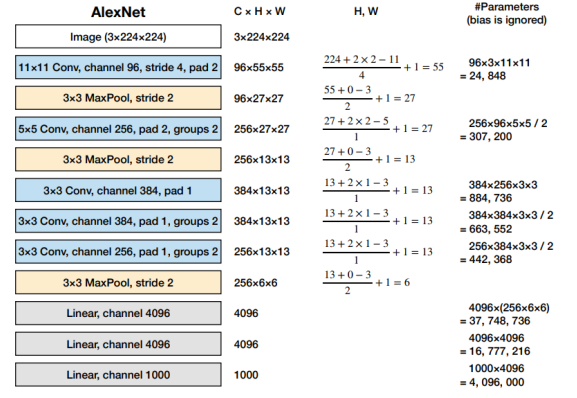
가장 하단의 channel의 개수 1000개는 output layer의 노드 개수로, 1000개 클래스의 분류문제이기 때문에 이렇게 설정하였다.
그 위는 hidden layer, 그 위는 full connected layer의 노드 개수를 말한다.
stride란, filter를 이동하는 픽셀 수를 말한다.
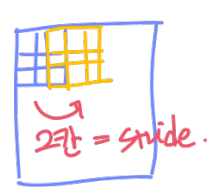
3. VGGNet (2014)
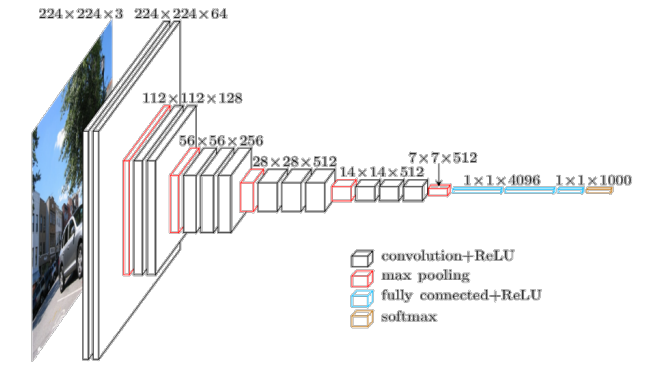
4. VGG-16 (2016)

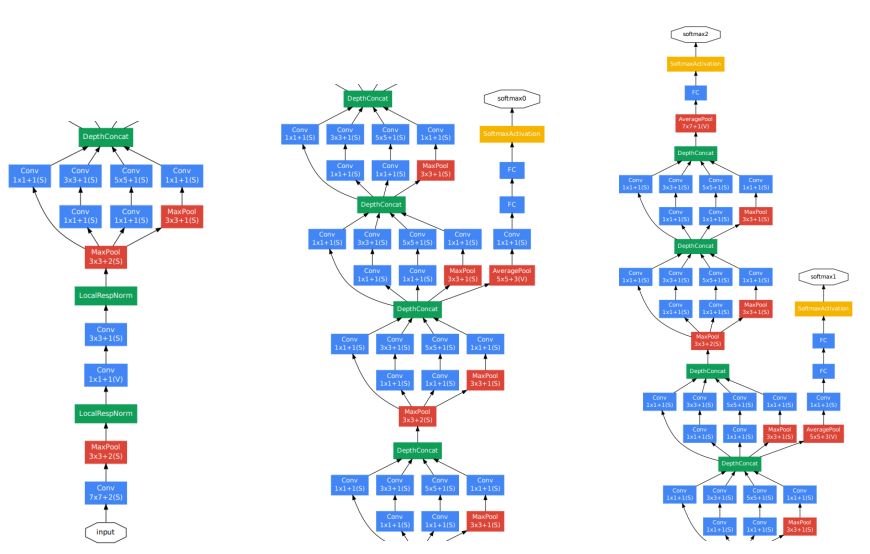
5. GoogleNet (2014)
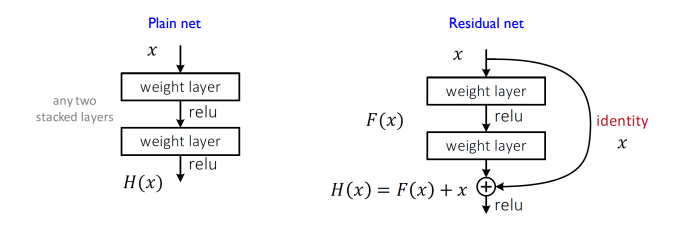
6. ResNet (2015)

layer를 몇개 생략할 수 있다. 이로인해 layer간의 drop-out regularization 효과가 발생하고, backpropagation 때 gradient 소실 문제를 어느정도 해결할 수 있으며, 앙상블 메서드의 이점도 얻을 수 있다.
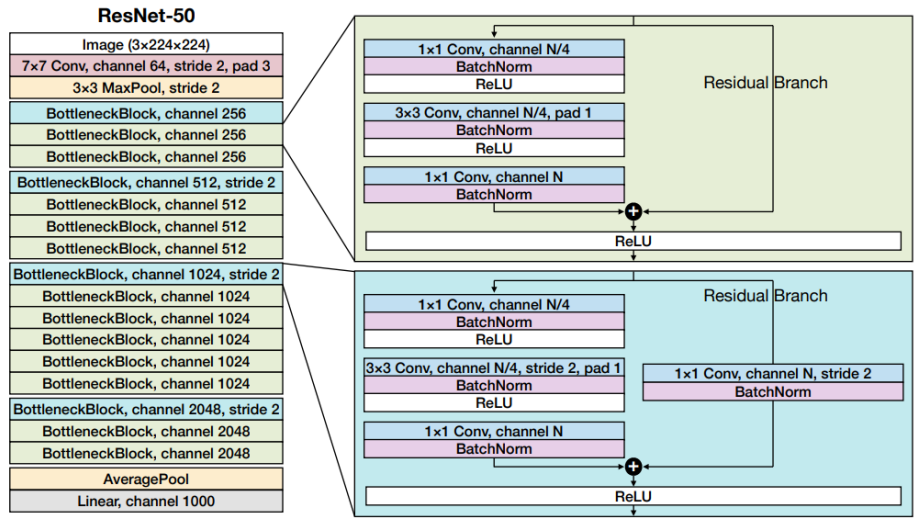
7. ResNet-50 (2016)
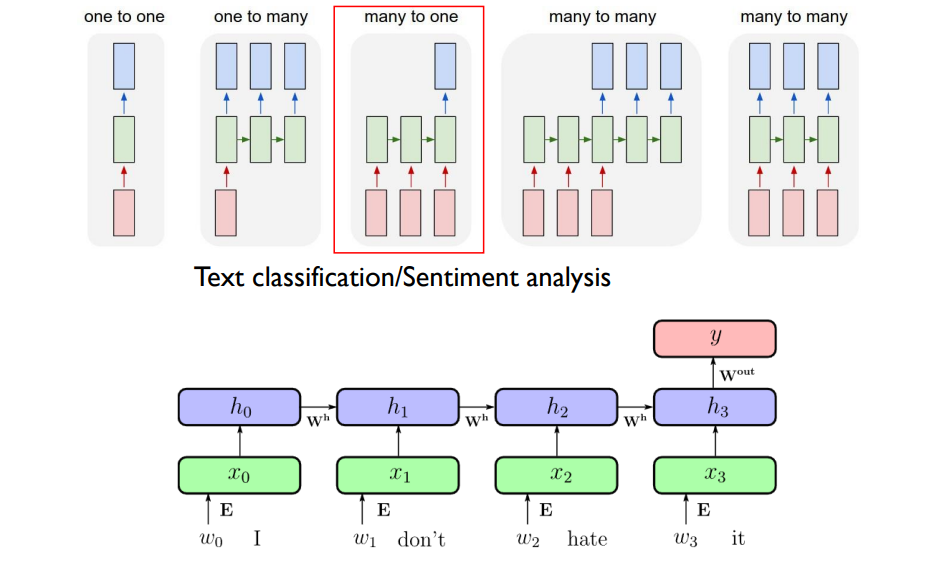
📁 Recurrent Neural Networks (RNN)
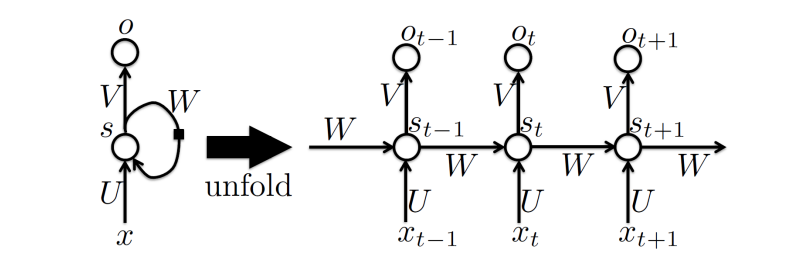
RNN은 1986년 Rumelhart et al.에 의해 제안된 모델로, sequential data에 의해 진행되는 neural network의 방식이다. 즉 data의 순서에 따라 연관성이 생기며, 주로 비디오의 frame과 같이 데이터 각각에 시간적 연관성이 있는 경우에 사용된다.
위 왼쪽 그림을 보면, input x에 의한 output s가 다시 노드 s로 돌아가는 형태를 띈다. 이전의 출력값을 다시 input값으로 사용하여 시간적 연관성을 학습하는 것이다. 이를 시간의 흐름에 따라 쭉 펼치면 오른쪽과 같은 그림이 된다. 이전 계산의 output인 s(t-1)과 다음 input값인 x(t)가 함께 계산되어 output s(t)를 도출하고, 이는 다시 다음 계산에 입력되는 방식이다.
이를 수식으로 나타내면 다음과 같다.
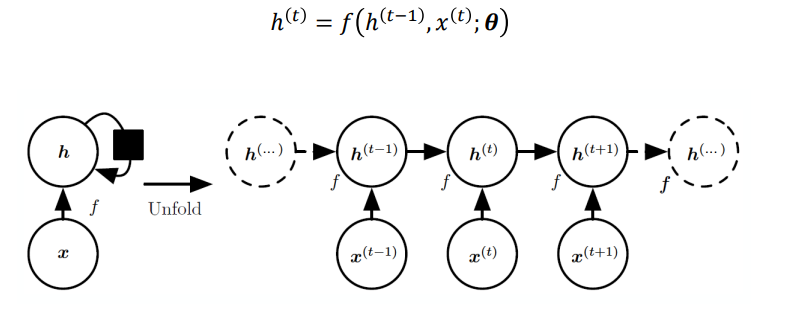
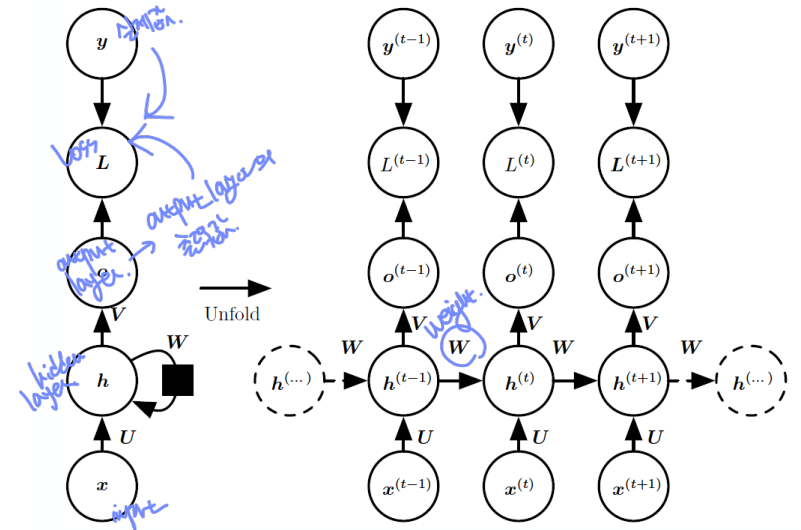
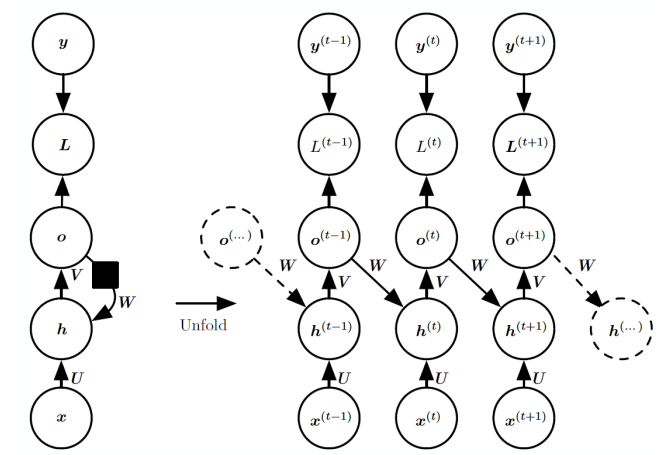
🌙 Forward propagation of RNN
U : input-to-hidden
W : hidden-to-hidden
V : hidden-to-output
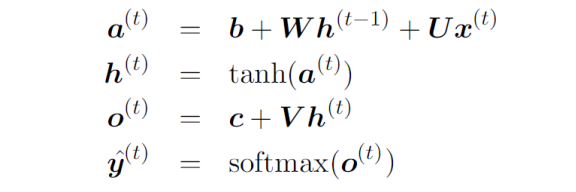
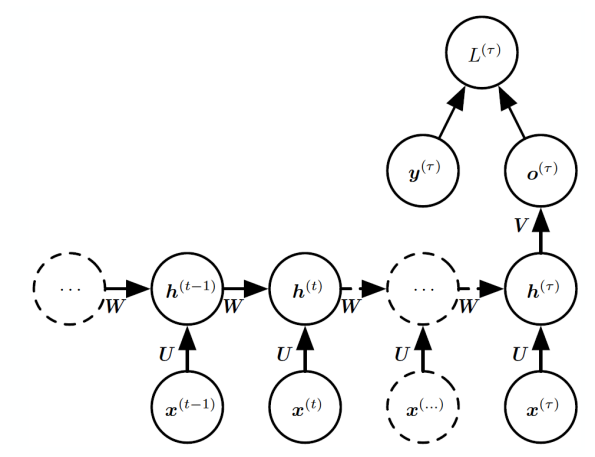
🌙 Backpropagation of RNN
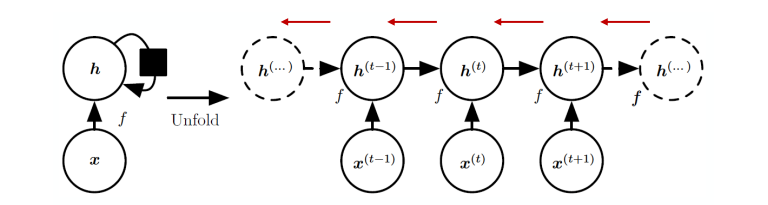
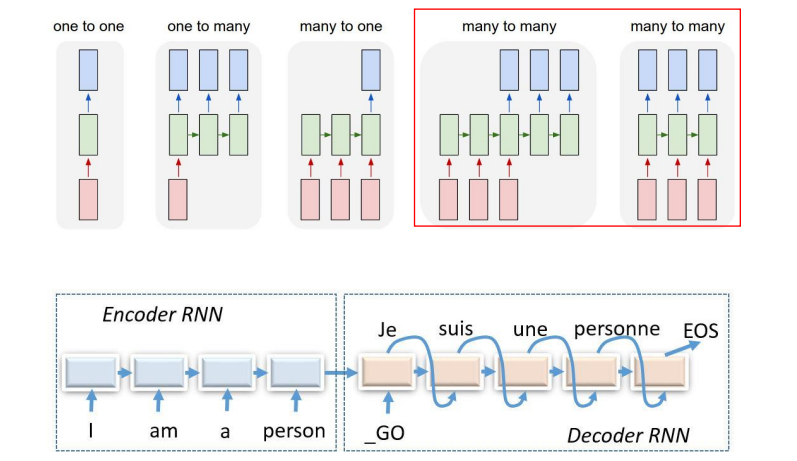
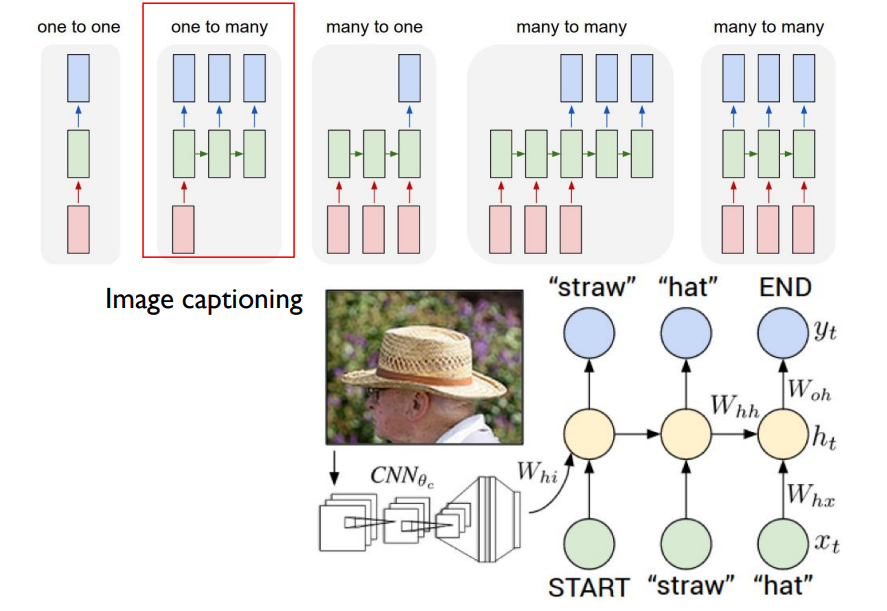
RNN의 예시는 다음과 같다.