목차
2023학년도 2학기 충남대학교 양희철 교수님의 기계학습 수업 정리자료입니다.
📁 Multiple Models

하나의 문제를 해결하기 위해서 꼭 하나의 모델을 사용하는 것이 아니라, 여러가지 모델을 함께 사용할 수 있다. 이렇게 모델을 여러개 만드는 방법은 두 가지가 있다.
1. training data 랜덤 추출
데이터셋에서 training data를 랜덤으로 추출하여 개별의 모델을 학습시키는 방식이다. 어떤 데이터가 training data로 선택되느냐에 따라 다른 모델이 생성되므로 이런 면에서 deterministic하지 않고 stochastic한 알고리즘의 형태를 띈다.
2. feature 랜덤 추출
data 내부의 feature들을 랜덤으로 추출해서 모델을 생성하는 방식도 있다. 예를 들어 데이터 하나가 feature x, y, z로 구성된다면, 그 중 x, z에 대한 컬럼만 선택할 수 있다는 뜻이다.
이렇게 모델을 여러개 생성하게 되면 각 모델은 전체 training data보다는 작은 범위의 데이터에 대해 학습되지만, 더 많은 개수의 모델을 만들 수 있다.
모델 여러개를 생성해서 결합시켜 문제를 해결하면 성능이 향상되며, 이런 방식을 Ensemble Method(앙상블 메서드)라고 한다.
🌱 Bias-variance dilemma
모델을 여러개 결합해서 사용하면 성능이 높아지는 이유는, bias와 variance 사이에 trade-off가 있기 때문이다.
기본적으로 모델을 생성하면 성능을 측정하기 위해 Bias와 Variance를 구한다.
- Bias란 어떤 모델의 예측값이 평균과 실제값의 차이. 즉 오차의 정도.
- Variance는 예측된 값의 분포.


θ가 실제값이고 θ^이 예측 값.
이때 bias와 variance는 trade-off 관계를 가진다.
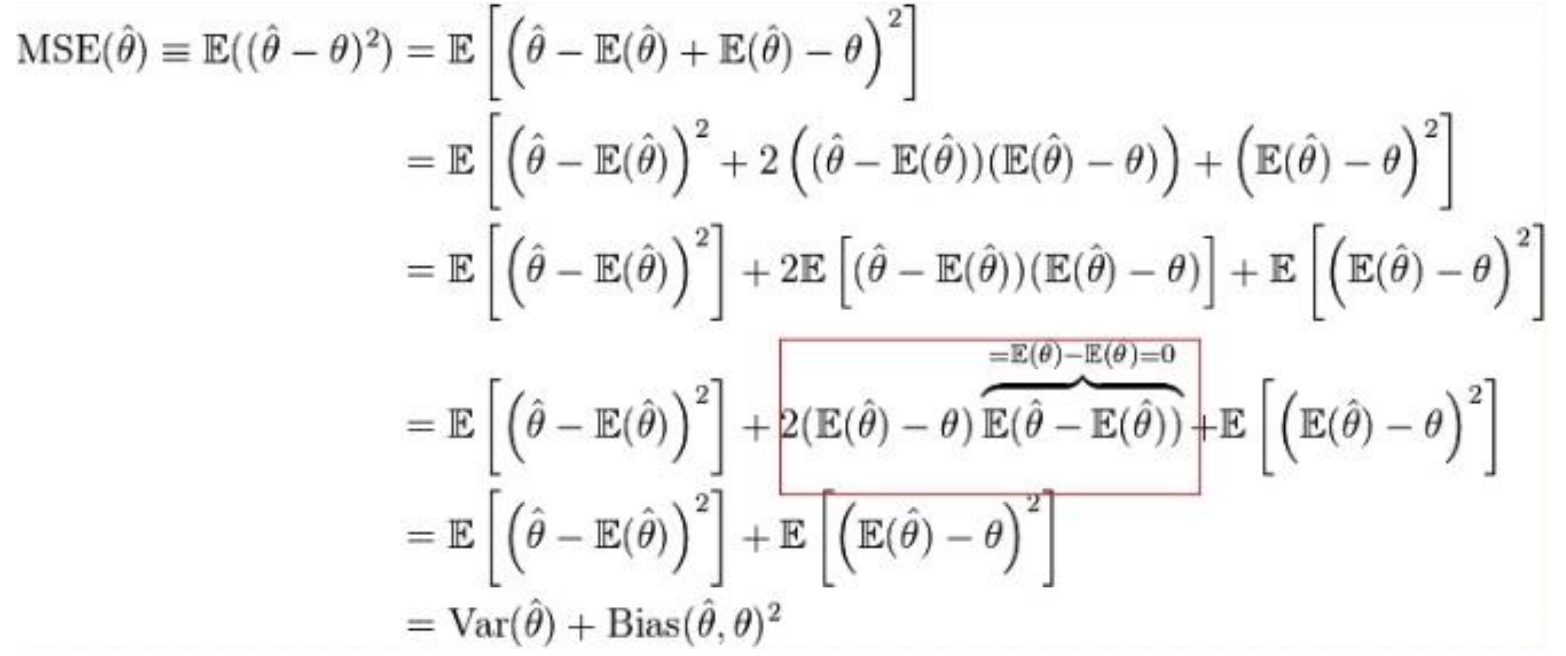
예를 들어 mean square error는 위와 같은 계산 결과 variance와 bias의 제곱의 합으로 계산된다. 이때 variance와 bias는 trade-off 관계이므로, 이 둘의 합이 가장 작아지는 최적의 구간을 찾아 MSE를 줄임으로써 최선의 모델을 찾을 수 있다.
Bias가 높을수록 Underfitting
Variance가 높을수록 Overfitting
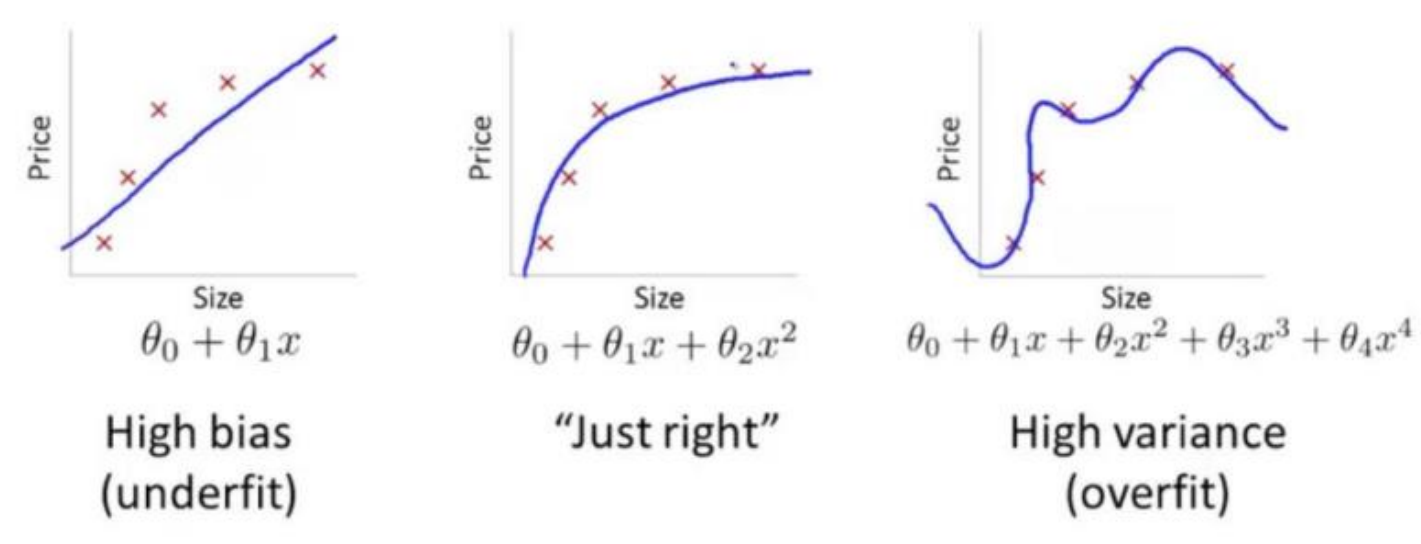
bias가 크다는 것은 예측값과 실제값의 차이가 평균적으로 크다는 뜻이므로, training data를 제대로 설명하지 못하는 underfitting 상태라고 볼 수 있고, 모델의 capacity를 늘려주면 bias는 줄어드는 대신 variance가 커지는데, variance가 크다는 것은 모델이 예측하는 값의 분포가 넓어진다는 뜻이므로 training data에 너무 잘 표현하는 overfitting 상태라고 볼 수 있다.
적절한 중간지점이 test data, 즉 아직 학습하지 않은 data에 대해 적절히 설명해 줄 수 있는 모델.
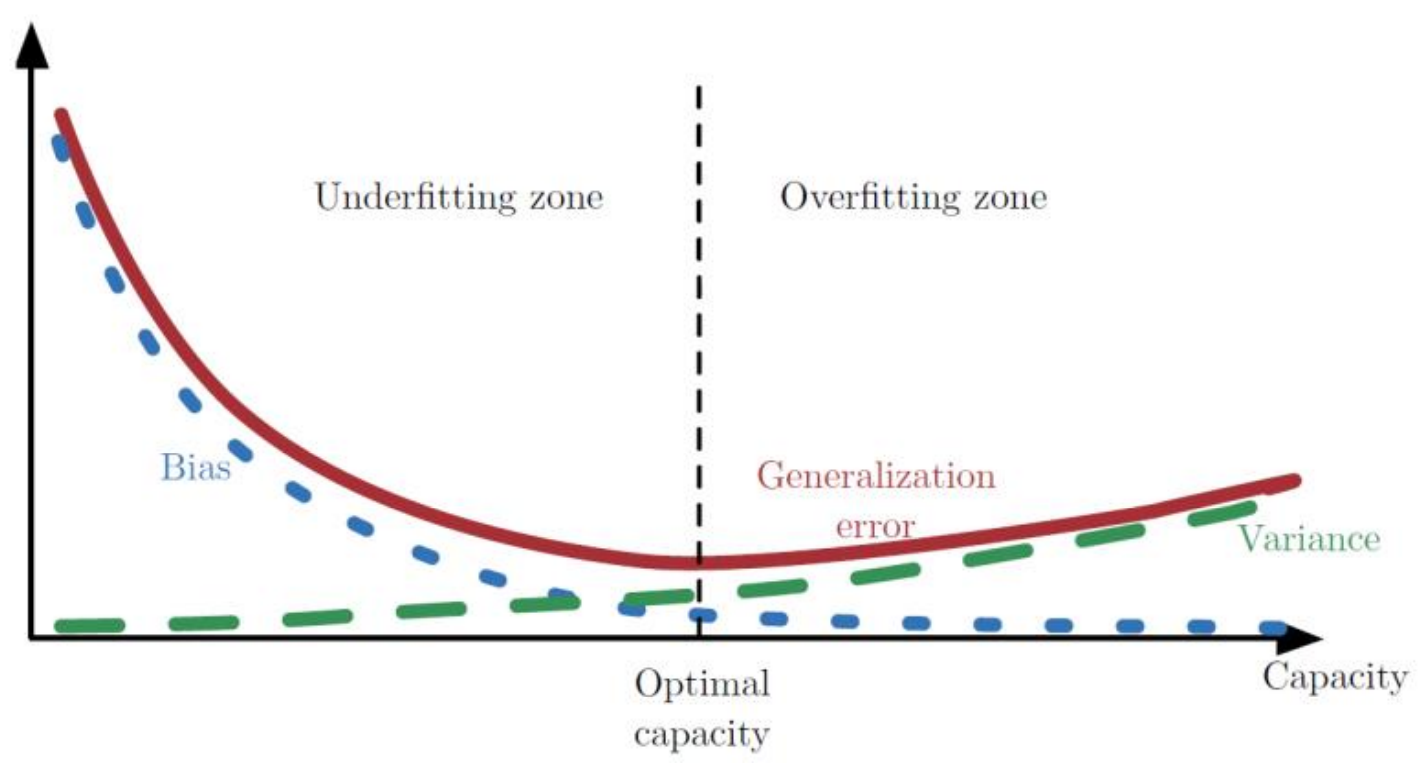
Generalization error는 Bias와 Variance의 합으로 나타낼 수 있다. 즉 optimal capacity보다 낮을때는 Bias가 높아서 gereralization error, 즉 training error가 크다. uunderfitting 상태. 특정 capacity를 넘어가면 bias 자체는 작고 예측갑과 기댓갑 사이의 오차는 주는데 vraince가 증가. training data에 대해 너무 과하게 표현해서 test data에 대한 일반화된 성능을 보일 수 없다.
즉 bias와 variance의 타협지점을 찾을 수는 있지만, 두 지표가 모두 최소가 되는 capacity를 찾는것은 힘들다.
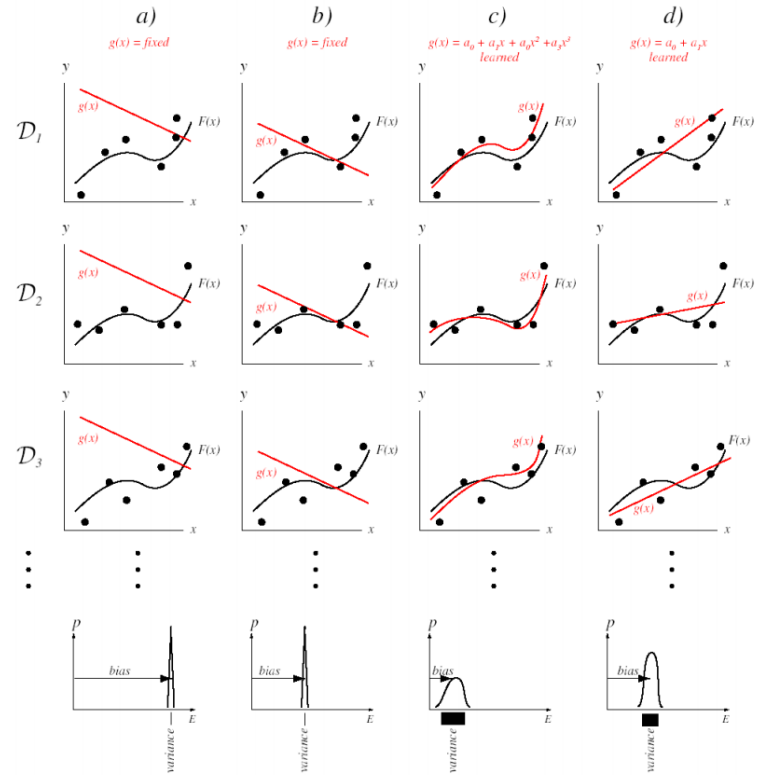
이거 이해 안감
빨간 선으로 표시된 g(x)는 학습 모델이고 고정적으로 표시된 검은 선의 F(x)는 정답 함수를 말한다.
c)의 학습모델 g(x)는 3차 다항식으로 복잡도가 높은데, 맨 아래의 그래프에서 확인할 수 있듯이 variance는 넓은데 bias는 작다
d)의 학습모델 g(x)는 1차식으로 복잡도가 낮고, c보다 vairance가 작으면서 bias는 커진다.
즉 모델의 복잡도가 크면 bias가 작고 variance가 크며, 복잡도가 낮으면 bias가 크고 variance가 작다.
❓ 근데 a랑 b는 학습 모델이 고정돼있는데 그러면 학습을 시켜서 나오는 모델을 쓰는게 아니라 아예 학습을 안시키고 그냥 함수 띡 던져주는 걸 말하는건가? 그리고 그냥 그 모델의 성능에 따라 bias가 크고 작아진다만 보여주는 거??
결과적으로, 한 모델의 성능을 평가하는 지표인 bias와 variance는 trade-off 성질을 지니고 있기 때문에, 하나의 모델만 사용하는 것 보다 여러개의 모델을 함께 사용하면 더 높은 성능을 기대할 수 있다.
📁 Ensemble Method(앙상블 메서드)
Ensemble Method란 한 개 이상의 base learner를 결합하여 예측 결과를 내는 방법을 말한다.
이때 base learner란 기본이 되는 모델을 말하는데, 앙상블 메서드에서 base learner 및 그들의 관점들은 모두 달라야한다.
앙상블 메서드의 종류에는 Bagging과 Boosting이 있다.
Bagging : bias가 낮고 variance가 높은 overfitting base learner들을 사용한다.
Boosting : bias가 높고 variance가 낮은 underfitting base learner들을 사용한다.
1. Bagging(Bootstrap aggregating)
각각의 모델은 bias가 낮은 대신 variance가 높다.
training data를 랜덤하게 샘플한 bootstrap을 구한 뒤, 각각 low bias를 갖는 base learner를 학습시킨다. 이후 variance를 낮추는 방식으로 모델들을 결합시켜 사용한다.
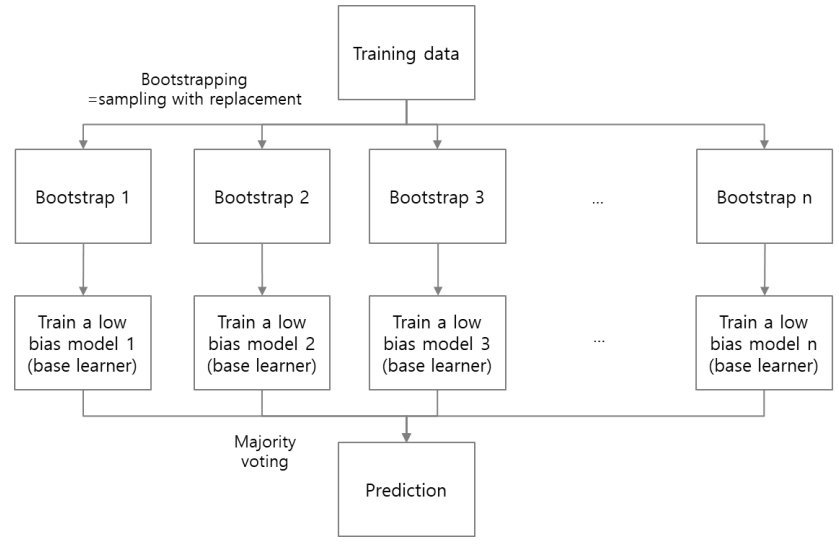
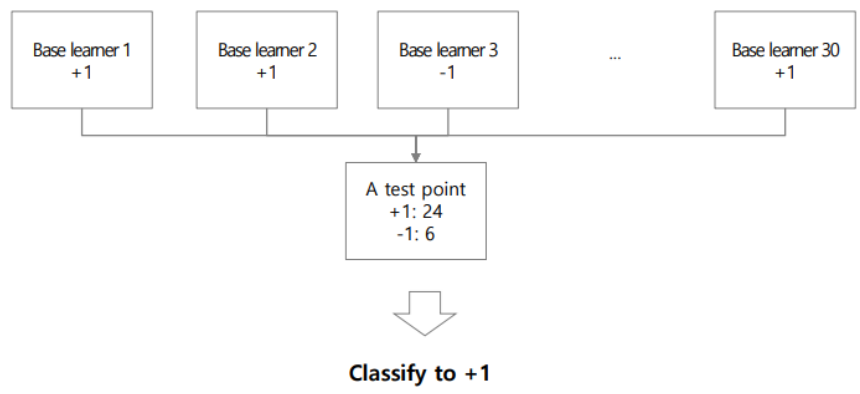
예를 들어 base learner를 총 30개 생성했다고 하자. 그 중 24개의 모델이 결과를 +1이라고 예측했고, 6개의 모델이 -1이라고 예측했다면 최종 결과는 +1이 된다.
bagging에서 사용되는 base learner들은 bias가 낮고 variance가 높으므로 overfitting될 가능성이 있는 모델들이다. 6개의 모델이 -1이라고 예측한 것은 해당 base learner가 overfitting으로 예측한 결과라고 추측하는 것이다.
🌱 Random forest
Random forest란 decision tree의 bagging 버전으로, feature를 랜덤으로 샘플링해서 약 50개 이상의 base learner 결정트리를 생성한 후 bagging하는 방식을 말한다.
feature를 랜덤으로 선택함으로써 개별 트리들간의 상관성을 줄여 예측력을 향상시킬 수 있다.

먼저 dataset에서 랜덤으로 추출한 bootstrap을 구한다. 이 bootstrap으로 트리를 생성할건데, 트리를 생성할 때 feature를 랜덤으로 추출해서 트리를 생성한다. 이를 계속 반복한다.
위 과정 중 4번줄에서 pruning을 하지 않는다는 대목이 있는데, 그 이유는 bagging이 기본적으로 bias가 낮고 variance가 높은 모델을 사용하므로 각각의 base learner들의 overfitting 발생을 굳이 막을 필요가 없기 때문이다.
모델의 성능을 계산할 때 OOB(Out of Bag) error를 사용한다. 트리를 생성할 때 전체 데이터set에서 일부를 샘플링하여 사용하는데, 모든 base learner들을 생산한 이후에 데이터셋에서 선택되지 않은 데이터 샘플들이 존재할 수 있다. 이 샘플들을 validation에 사용하여 구한 error를 OOB error라고 한다.
2. Boosting
각각의 모델은 bias가 높은 대신 variance가 낮다.모 base learner들을 parallel하게 실행시켰던 bagging과 달리, sequantial learning 방식을 통해 모델의 성능을 향상시킨다.
종류에는 AdaBoost, GradientBoos, XGBoost 등이 있다.
🌱 AdaBoost
Boosting 방식을 사용하면 각 모델이 sequantial하게 학습되므로, 앞서 학습된 모델의 결과가 다음 모델에게 영향을 끼칠 수 있다.
AdaBoost는 현재 모델에서 학습이 잘 되지 않은, training error가 높은 데이터들이 그 다음 모델을 학습할 때 더 많이 샘플링 될 수 있도록 선택될 확률을 높이는 방법이다.
다음은 AdaBoost 알고리즘의 작동 과정이다.

먼저 모든 데이터에 대한 가중치 w를 동일하게 설정한다.
첫번째 모델을 학습한 후, 모든 데이터 m에 대한 error를 구하고, 이후 해당 데이터 m이 선택될 확률을 결정할 알파를 계산한다. (d)와 같은 과정을 통해 가중치를 계산하여 업데이트한 뒤, 이를 반복한다.
AdaBoost 방식의 예시에는 다음과 같은 경우가 있다.
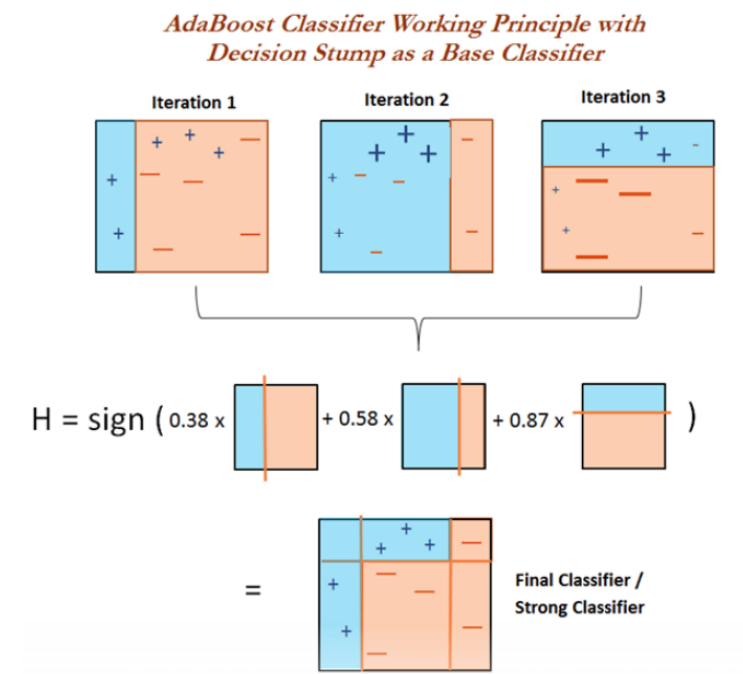
위 그림에서, 세가지 모델을 살펴보면 2번째 base learner의 일부 +와 3번째 base learner의 일부 -가 크기가 큰 것을 볼 수 있다. 해당 데이터들이 직전 모델 학습에서 잘 학습되지 않았던 데이터들이기 때문에, 현재 모델 학습때 선택될 확률을 높인 것이다.
이런 방식을 사용해 모델의 bias를 낮추는 방식으로 결합한다.
🌱 Gradient Boost
Gradient Boost는 다음 모델이 gradient를 줄이는 방향으로 학습되도록 한다.
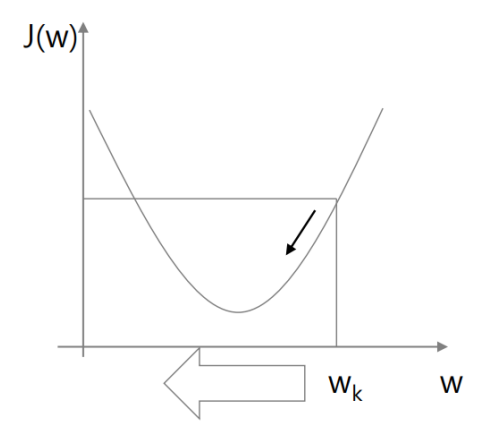
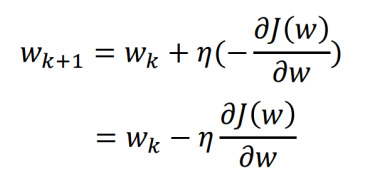
다음 step의 방향은 역방향임을 오른쪽 마이너스 기호로 표시하고, learning rate를 적용한 위 공식의 결과로 얼마나 이동할지를 결정한다.
learning rate를 적용한 현재 위치에서의 J(w) 미분 값을, 현재 w(k)값에서 빼서 다음 w(k+1)값을 결정한다. 즉 미분값인 gradient가 클수록 더 많이 이동한다. 우리는 기울기가 0이 되는 값을 찾고자 하는 것이므로, 기울기가 0보다 클수록 더 많이 움직여야 빠르게 찾을 수 있기 때문이다.
GreadientBoost for Regression
다음은 GradientBoost 알고리즘으로 Regression 할 때의 작동 과정이다.
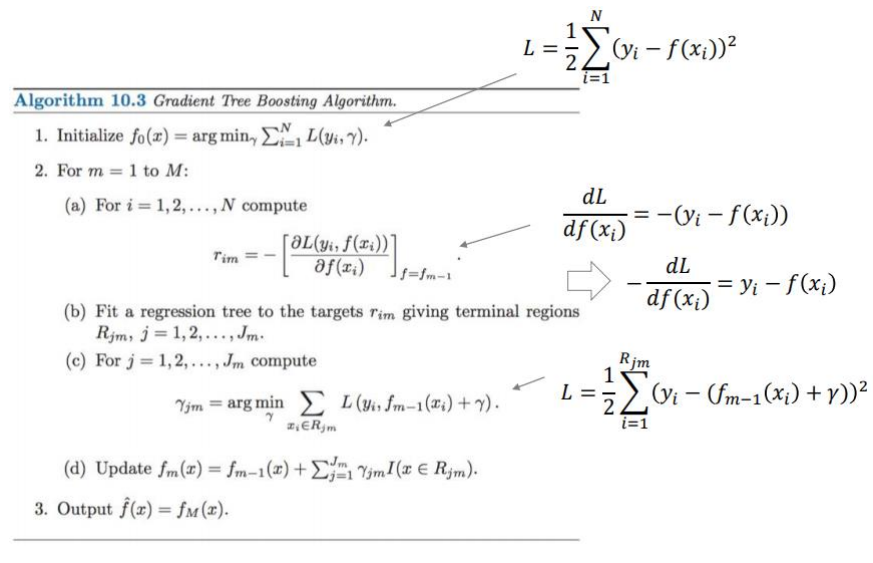
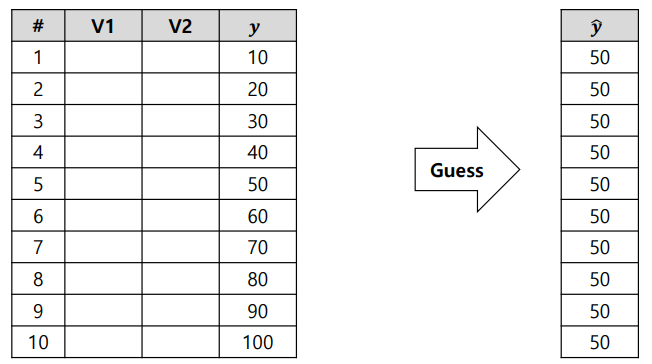
GradientBoost로 Regression하는 예시를 들어보자.
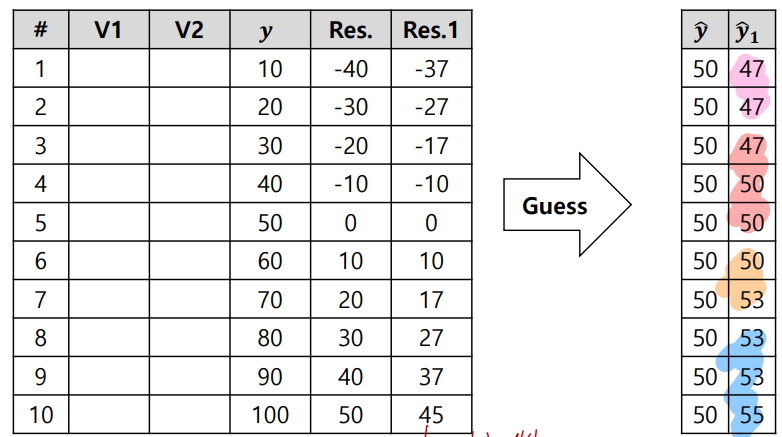
1) Initial guess (with average)

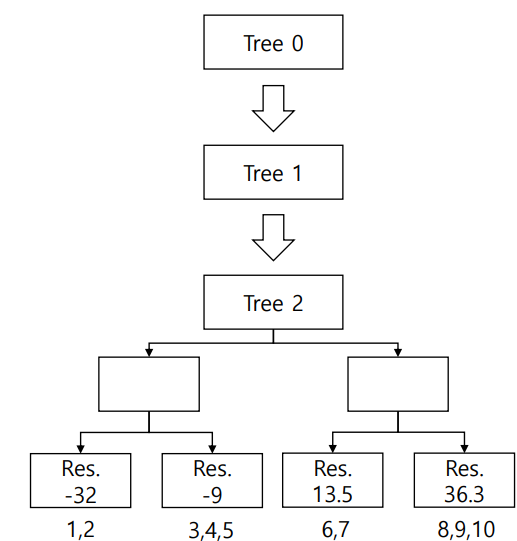
2) Calculate pseudo residuals & fit a tree with them
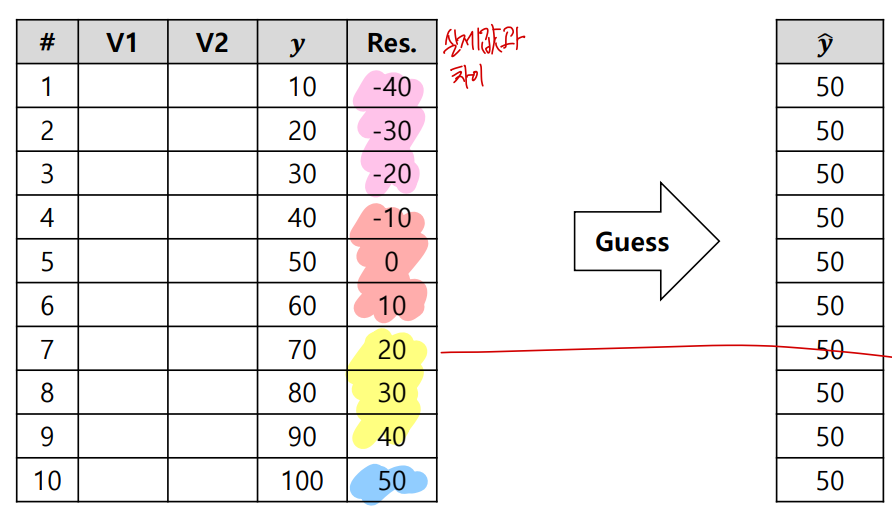
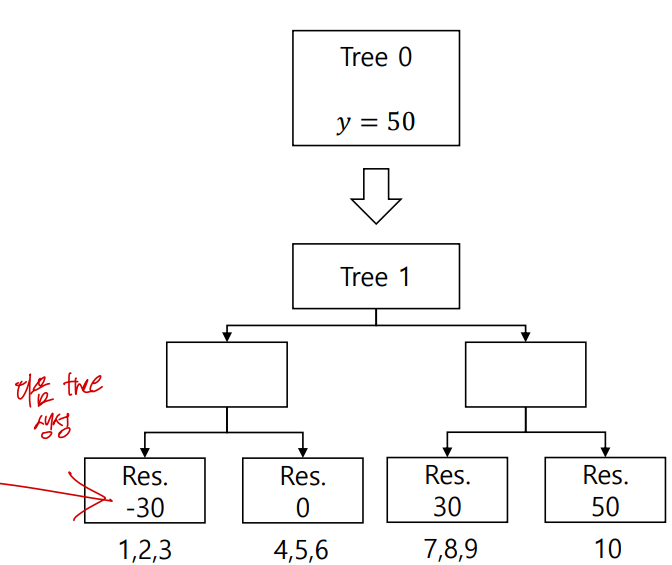
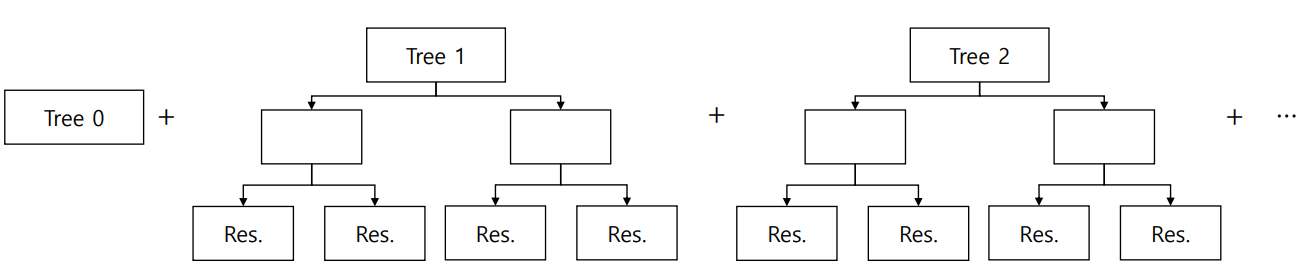
3) Make a new prediction with all trees: Tree 0 + a * Tree 1
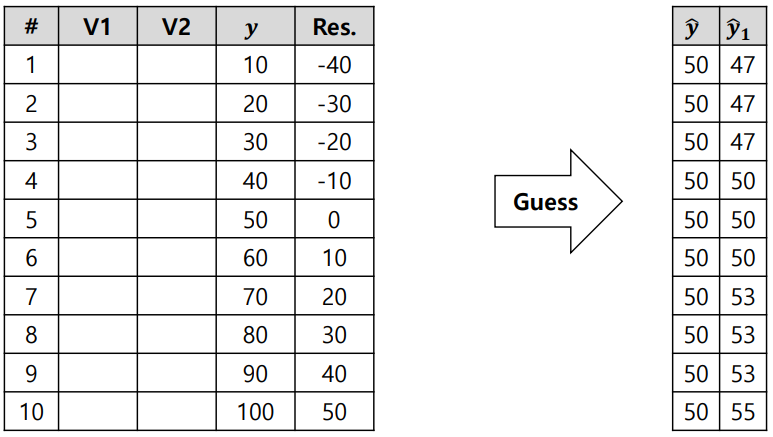
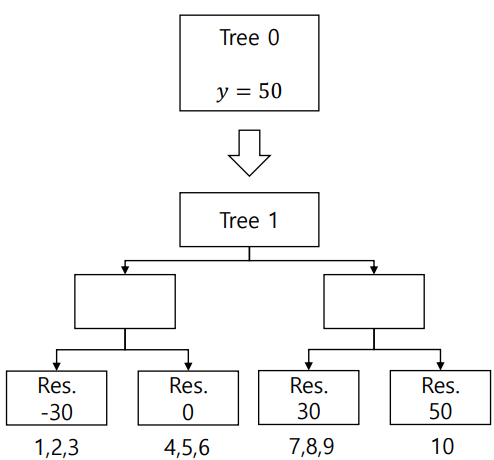
4) Recalculate pseudo residuals & retrain a new tree
5) Make a new prediction with all trees: Tree 0 + a∙Tree 1 + b∙Tree 2
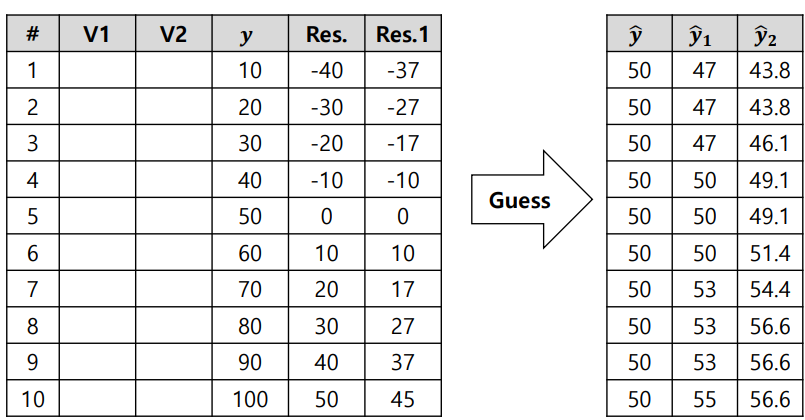
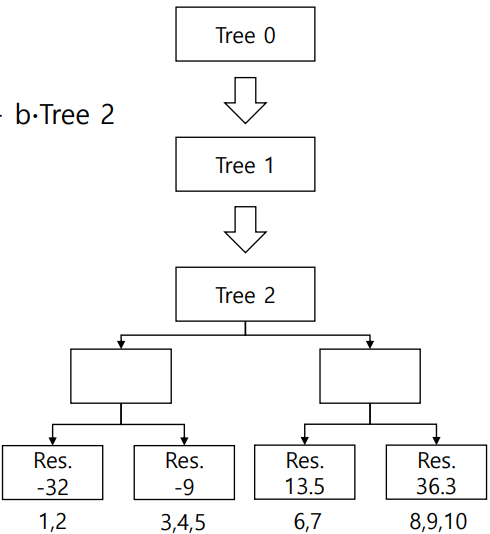
6) Until it reaches a stopping criterion
GreadientBoost for Classification
다음은 GradientBoost 알고리즘으로 Classification 할 때의 작동 과정이다.


GradientBoost로 Classification 하는 예시를 들어보자.
🌱 XGBoost

참고
최선의 모델을 찾아서 (부제: bias와 variance 문제 이해하기)
니모 아빠 말린과 친구 도리가 니모를 찾아 넓은 바다로 모험을 떠났다면, 우리는 데이터의 바다에서 최선의 모델을 찾아 오늘도 모험을 떠납니다. 다른 점이 있다면 말린의 아들 니모는 유일한
medium.com
https://gaussian37.github.io/machine-learning-concept-bias_and_variance/
머신러닝에서의 Bias와 Variance
gaussian37's blog
gaussian37.github.io
https://sungkee-book.tistory.com/7
[머신러닝] 편향과 분산의 의미
지난번 포스팅에 이어, 이번 글에서는 1) 편향과 분산이 의미하는 바를 그림으로 쉽게 이해하고, 2) 편향, 분산과 모델 복잡도 간의 관계에 대해서 알아보도록 한다. 본 글은 고려대학교 강필성
sungkee-book.tistory.com



