목차
2023학년도 2학기 충남대학교 양희철 교수님의 기계학습 수업 정리자료입니다.
📁 의사 결정 트리(DT, Decision tree)

의사결정트리란, 입력 값에 따라 목표 값을 예측할 때 사용하는 트리 모양의 모델을 말한다.
기본적으로 Decision Tree로 데이터를 분류할 때는 위에서 아래로 진행하며, 리프노드에 도착할 때 까지 연속적으로 노드를 방문하여 분류하는 방식이다.
각 노드에서 묻는 질문은 특정 속성과 관련되고, 아래로 향하는 화살표 링크는 해당 속성으로 가능한 값들을 나타낸다.
Decision Tree는 학습 단계에서 greedy method를 쓰기 때문에 연산량이 많지 않고, 한번 트리를 생성한 후 데이터를 분류하기 위해서 모델을 거치도록만 하면 되기 때문에 사용이 용이하지만, 성능 면에서 한계가 있다는 단점이 있다.
분류는 IF-THEN 룰에 의존하여 진행된다. 예를 들어, 위 루트 노드에서 IF문의 조건으로 색깔이 초록색인지, 노란색인지, 빨간색인지 분류하며, 만약 초록색인 경우 이다음으로 크기를 비교하는 THEN 문을 수행한다.
이때 똑같은 IF-THEH 룰을 가진 프로그래밍이더라도 IF문에서의 조건을 사람이 직접 정해주는지 기계가 training data들로 학습하여 선정하는지에 따라 머신러닝일수도 머신러닝이 아닐 수도 있다.
🌱 DT의 특징
1. Recursive partitioning
노드와 노드 사이의 IF-THEN 분기를 반복하여 재귀적으로 분류한다. 예를 들어 색깔이 초록색인지 노란색인지를 먼저 구분한 뒤, 크기가 큰지, 중간인지, 작은지에 대한 구분은 색깔이 초록색으로 분류된 이후의 데이터셋에 대해서만 진행한다.
2. Explicit rule extraction
분기마다 명확한 기준을 세울 수 있다.
3. Interpretability
결과를 해석할 수 있으며, 해당 결과가 나온 과정을 설명할 수 있다. 분류의 결과가 수박이라면, 결정트리 내에서 색깔 및 크기를 분류하는 경로를 거쳐왔기 때문에, 색깔이 초록색이고 크기가 컸기 때문이라고 말할 수 있다.
4. Axis-orthogonal partitioning
축과 직교하게 파티셔닝된다.
5. Greedy method
분류 결과를 끝까지 모두 확인하고 나누는 것이 아니라, 탐욕 알고리즘을 수행하여 지금 당장의 상황에서 가장 좋은 partitioning을 수행한다.

split 이후 결과를 확인하고 되돌아오지 않고, 지금 당장의 결과가 좋은 split을 진행하기 때문에 계산이 쉽지만, local optimum에 빠지기 때문에 최종적인 성능이 떨어진다.
6. Robust to nominal variables outliers, missing values
1) nominal variables
수치가 아닌 값들을 말한다. 예를 들어 초록, 노랑, 빨강 등 색깔 값은 수치가 아님에도 decision tree의 분류조건이 될 수 있다.
2) outliers

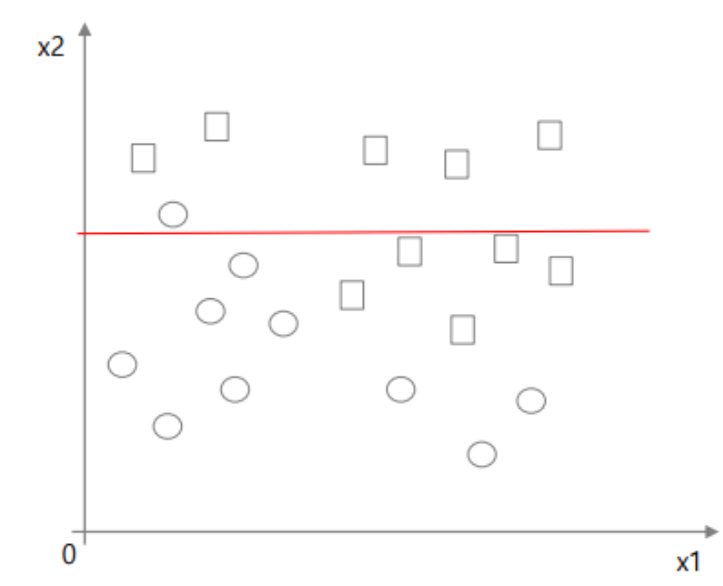
outlier에 대해 둔감하다. 예를 들어 K-NN 알고리즘과 같은 경우, 위 빨간색으로 표시된 outlier 데이터들에 대해 민감하게 반응하지만, decision tree는 outlier가 존재해도 크게 영향을 받지 않는다.
3) missing value(결측치)
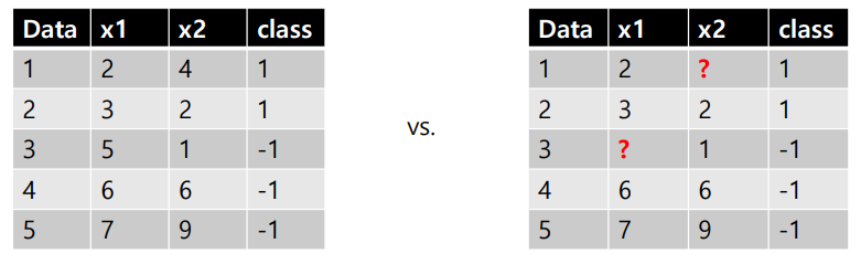
missing value란 데이터에 값이 없거나 손상된 경우를 말한다. decision tree는 missing value에 의해 큰 영향을 받지 않기 때문에 이를 포함해서 학습이 가능하다. missing value에 대한 분기를 따로 만든다던가, missing value인 경우 랜덤하게 분류한다던가 등의 방법을 사용해서 쉽게 해결할 수 있다.
7. variable selection
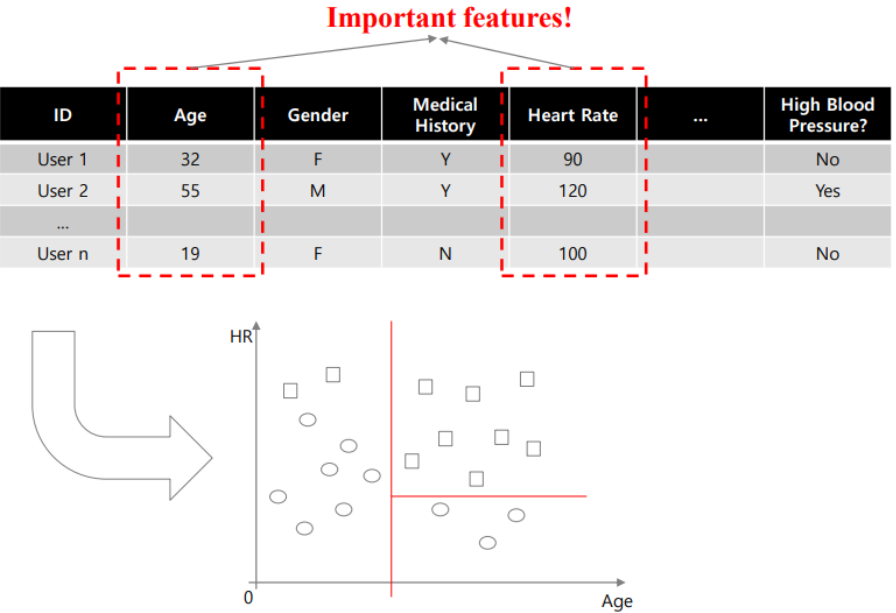
분기의 순서가 feature의 중요도를 나타낸다.
🌱 용어
Leaf Node에 클래스 하나의 값들만 남는 경우, training data에 의해 분류가 잘 되었음을 나타낸다.
📝 예시1
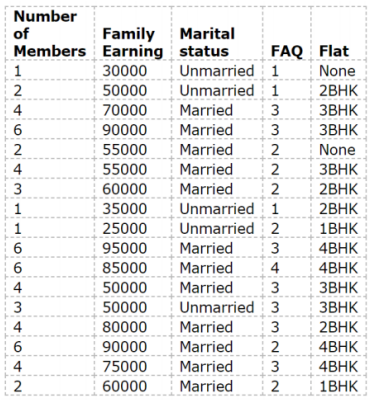
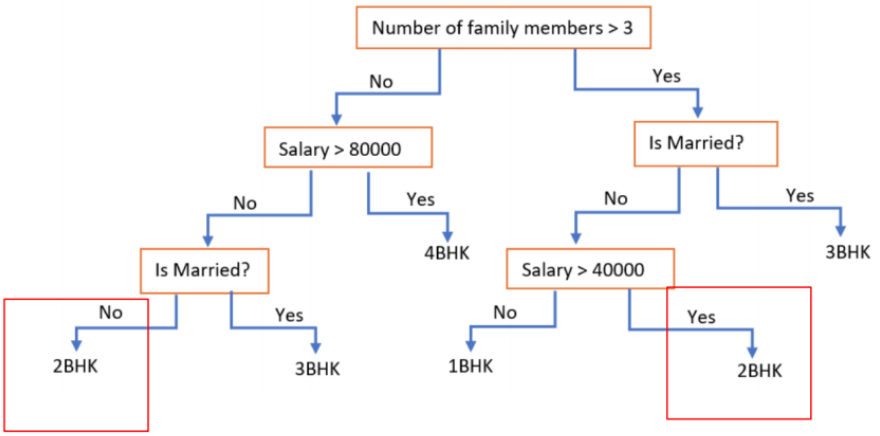
왼쪽과 같은 training data를 가지고 오른쪽 decision tree 생성이 가능하다.
📝 예시2
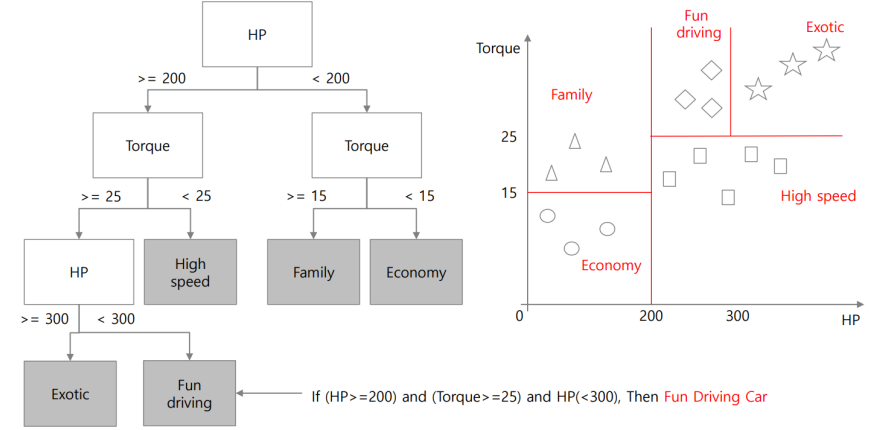
📁 Desicion rule
Decision Tree를 생성하기 위해 고려해야 할 규칙을 알아보자.
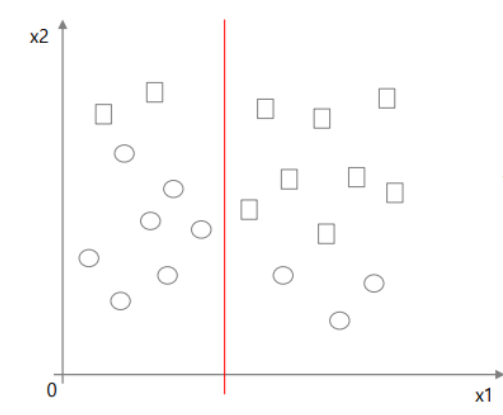
1. Axis-orthogonal
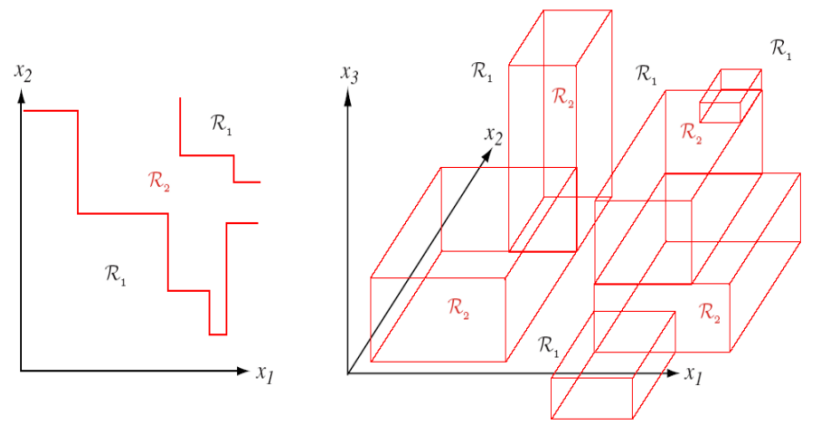
그래프의 축이 feature일때, 파티셔닝을 feature를 기준으로 진행해야 하므로 즉 축과 직교하게 파티셔닝해야한다.
2. Impurity Drop
Impurity란 불순도 혹은 복잡도 라고 불리며, leaf node 내에서 얼마나 많은 클래스가 섞여있는지, 즉 분류 결과가 다른 클래스의 값과 어느정도 섞여있는지의 정도를 나타낸다.
Decision Tree를 생성할 때, input variable중 어떤 variable을 가지고 나누어야 하고, 그 variable 안에서 어떤 값을 기준으로 파티셔닝 해야할지를 결정하는 기준이 된다.
즉 Decision Tree를 만들 때는 불순도를 낮추는 방향으로 생성해야한다.
불순도(impurity)를 측정하는 방법에는 여러가지가 있다.
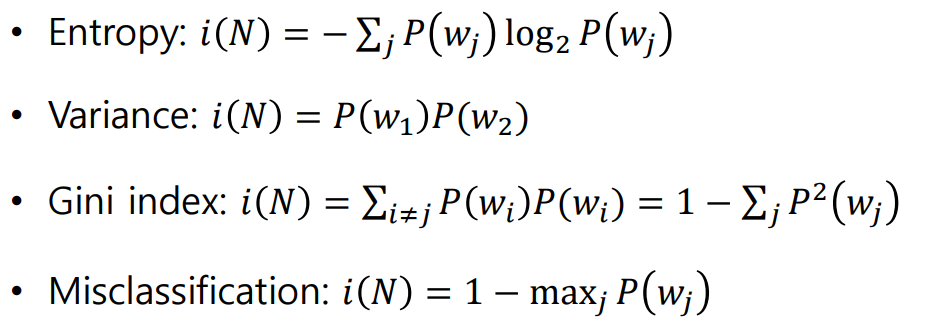
P(wj)는 wj라는 클래스에 데이터가 존재할 확률을 말한다.
Entropy는 불확실성이라고도 한다.
Entropy, Gini Index, Misclassification은 값이 조금씩 다를지언정 그 경향이 비슷해서 계산을 진행할 때 어떤 방법을 채택하느냐에 따라 결과가 달라질 수는 있겠지만 어떤 방법을 사용해야하는지에 대한 정답은 없다.
예를 들어 다음과 같은 경우에서 Entropy와 Gini Index를 계산해보자.
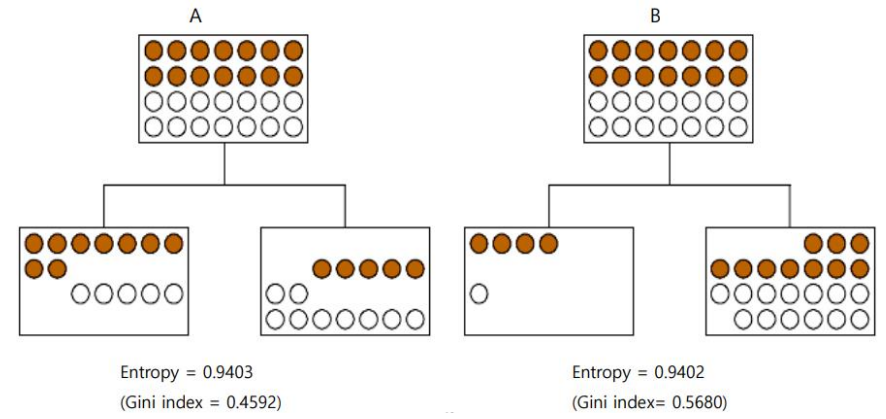
A와 B의 Entropy 값은 아주 비슷하지만, Gini Index는 상대적으로 차이가 크다.
3. Information Gain
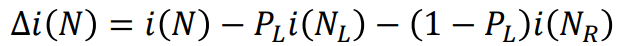
Decision Tree를 형성하는 과정에서, split을 진행할 때 마다 불순도가 얼마나 떨어지는지를 계산할 수 있어야 최적의 파티셔닝이 가능하다. 이는 현재의 불순도 i(N)에서 split 이후 왼쪽의 불순도인 i(N(L))과 오른쪽의 불순도 i(N(R))에 각각 왼쪽으로 분류될 확률과 오른쪽으로 분류될 확률을 곱해서 뺄셈하는 위와 같은 계산 과정을 통해 구할 수 있다.
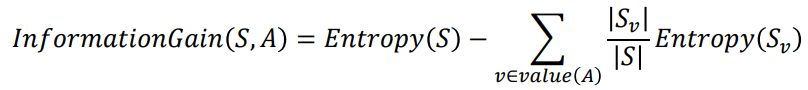
위 과정을 Entropy를 이용하여 계산하는 공식은 위와 같이 표현할 수 있고, Information Gain이라고 부른다.
예를 들어 다음과 같은 경우의 Entropy와 Information Gain을 계산해보자.
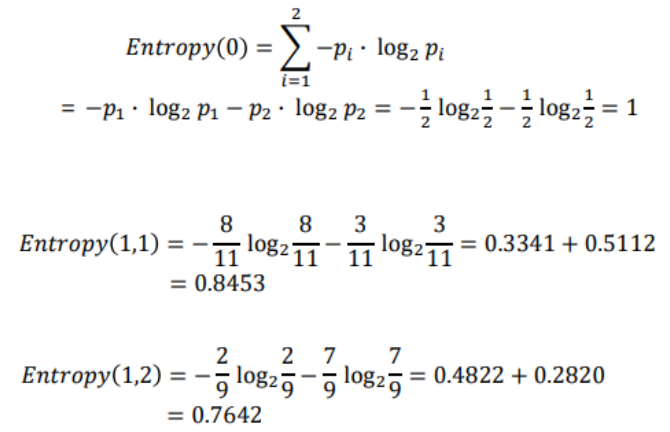
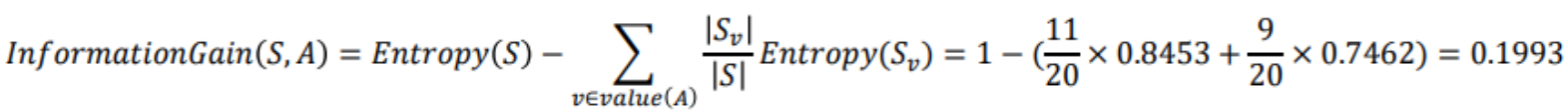
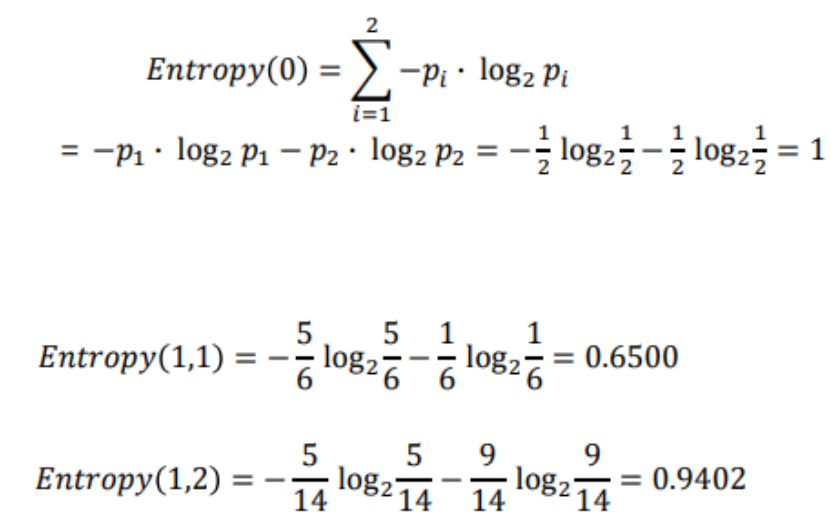
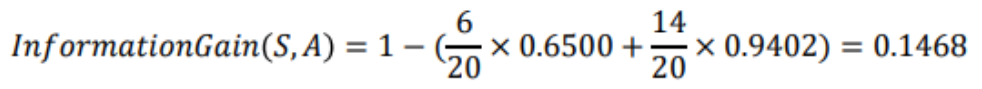
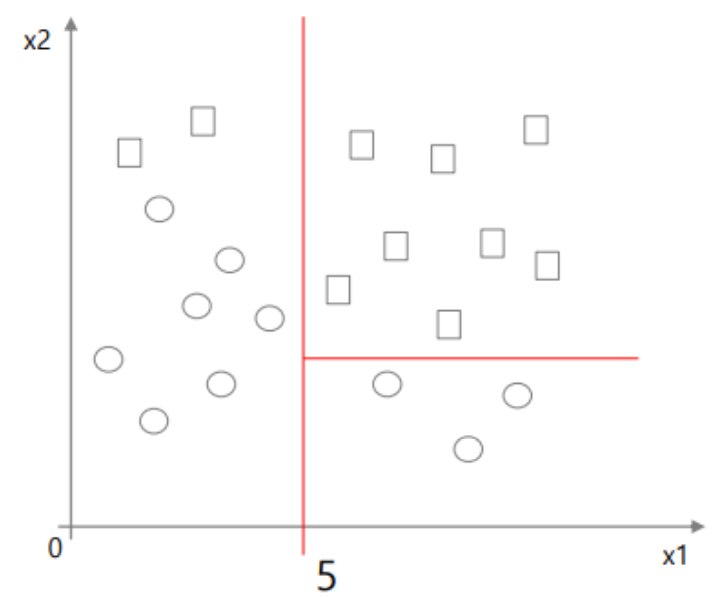
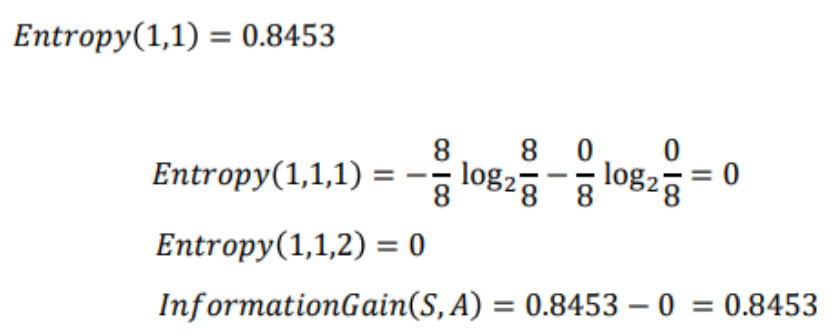
최종적으로 다음과 같은 Decision Tree가 만들어진다.
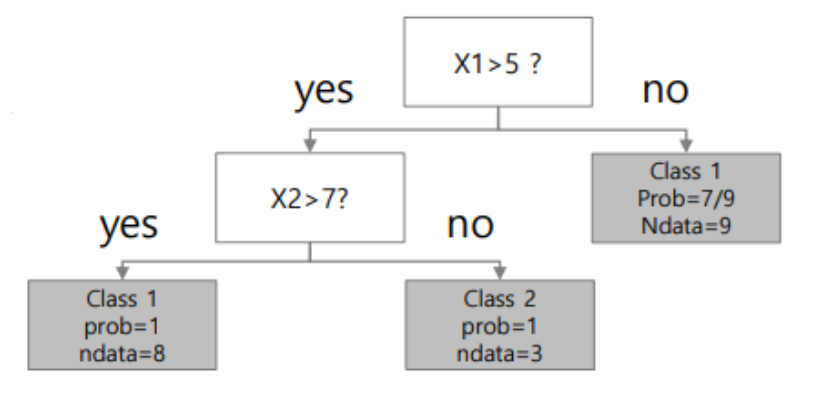
4. Limitation of the size of tree
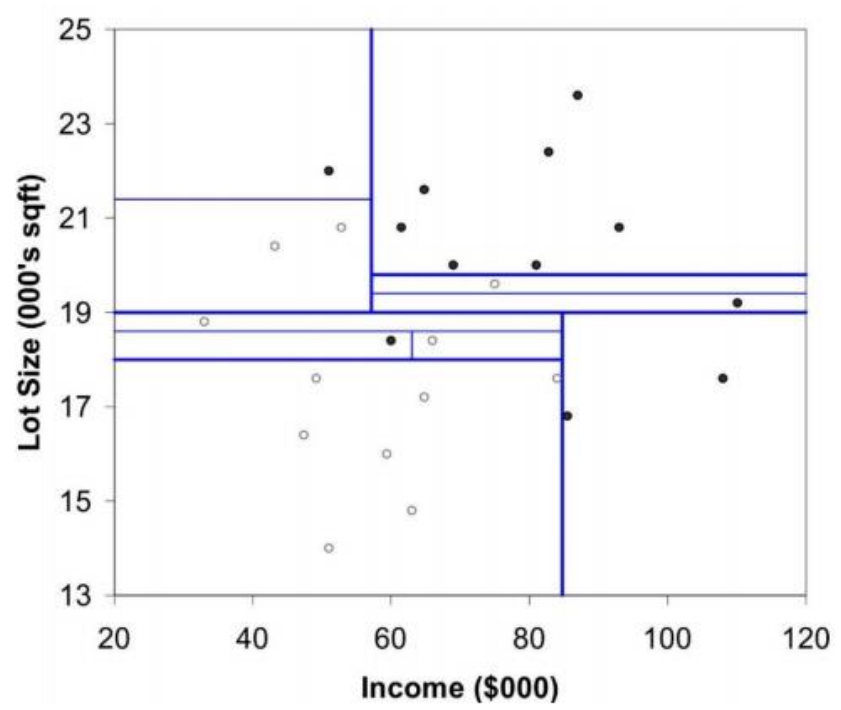
모든 분기의 entropy가 0인 트리, 즉 모든 결과에 다른 클래스가 속하지 않고 불순도 없이 분류된 트리를 Full Tree(Full grown tree)라고 부른다.
Decision Tree를 생성할 때 Recursive Partitioning을 계속 수행하다보면 최종적으로 Full Tree를 만들 수 있을 것이다. 하지만 무조건 불순도가 0이라고 해서 좋은 트리는 아니다. training data에 대한 성능이 높더라도 test data에 대한 성능이 낮을 수 있기 때문이다.
위와 같은 이유로 트리가 크면 클수록 overfitting 문제가 발생할 수 있다. 하지만 그렇다고 파티셔닝을 너무 적게 진행하게 되어 트리의 크기가 작아지면 underfitting 문제도 발생할 수 있다. 때문에 어디까지 파티셔닝을 진행해야하는지에 대한 기준도 구해야한다.
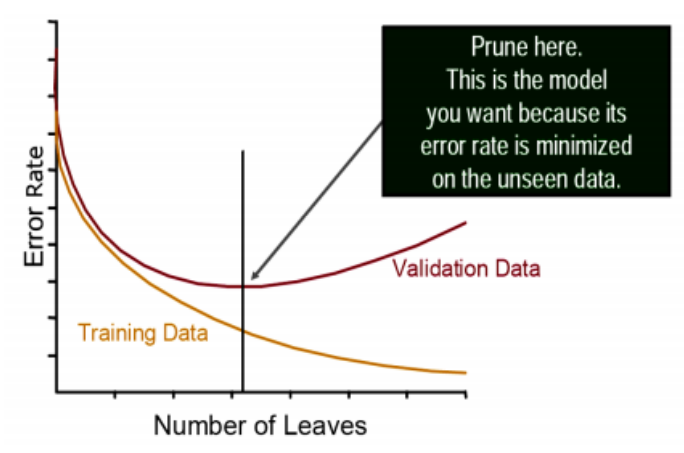
파티셔닝의 정도, 즉 트리의 크기를 결정하기 위해서는 기본적인 머신러닝처럼 training data 외에 test data를 준비하여 test data에 대한 성능을 측정해야한다.
Decision Tree에서는 전체 데이터의 약 70퍼센트를 training data로 사용하고, 30퍼센트를 test data로 사용한다. 리프노드의 개수가 곧 트리의 크기를 나타내므로, 트리의 크기가 커질수록 training data에 대한 loss는 줄어들지만 test data의 loss는 줄어들다가 어느 지점부터 증가한다. 해당 지점을 구함으로써 결정트리의 적정 크기를 결정할 수 있다.
위 그래프에서는 트리의 크기를 리프노드의 개수라고 가정하고 최대 리프 노드 개수를 제한하였지만, 이외에도 최대 깊이 혹은 리프노드가 가질 수 있는 최소 데이터 개수 등의 capacity들을 제한할 수도 있다.
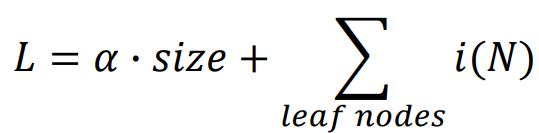
혹은 Regularization 기법을 사용할 수 있다. Loss를 계산할 때 각 리프노드의 불순도만 계산하는 것이 아니라, 트리의 크기를 함께 더해주어 둘 사이의 균형을 맞출 수 있도록 한다.
🌙 Pruning
Pruning(가지치기)란 트리의 크기를 결정할 때 일반적으로 사용하는 방법으로, 가지가 존재하면 불순도가 적어지는 대신 트리의 크기가 커지므로 두 값을 비교함으로써 해당 가지를 제거할지 제거하지 않을지 결정하는 방법이다.
test data를 준비할 필요가 없어지지만, 계산 과정이 추가된다.
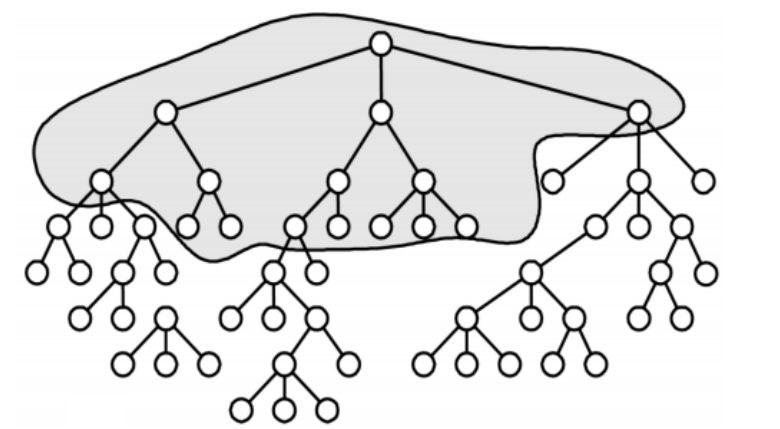
Pruning 알고리즘의 순서는 다음과 같다.
- training data에 대한 full tree를 생성한다.
- Full tree에 대한 Cost와 해당 트리의 일부분인 sub tree에 대한 Cost를 계산한다.
- Full Tree Cost > Sub Tree Cost인 경우 해당 sub tree를 남겨두고, 그렇지 않은 경우 제거한다.
이때 트리 T에 대한 Cost는 training error와 tree size의 합으로, 다음과 같이 계산한다. 이때 알파(a)는 두 값 사이에 두는 가중치이다.
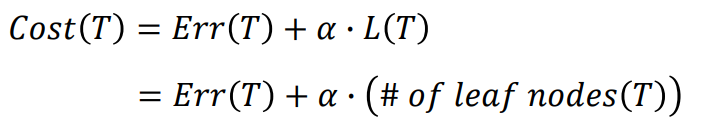
pruning을 해도 Cost가 증가하지 않는다면, 해당 노드를 제거한다. 위와 같이 Cost를 기반으로 Pruning하는 방법을 Cost-Complexity Pruning이라고 부른다.
📁 Decision tree 생성 알고리즘
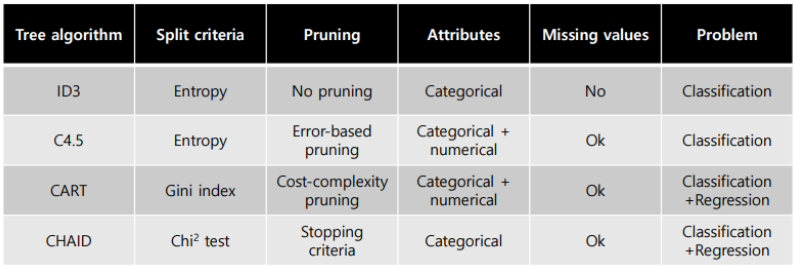
decision tree를 생성하는 알고리즘은 여러가지가 있는데, 그 중 CART를 주로 사용한다.
📁 Nonlinear Splits
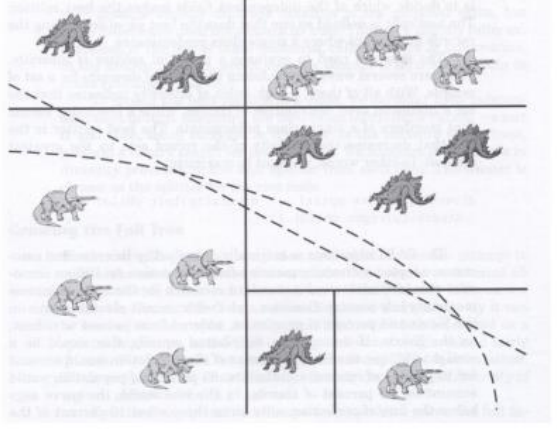
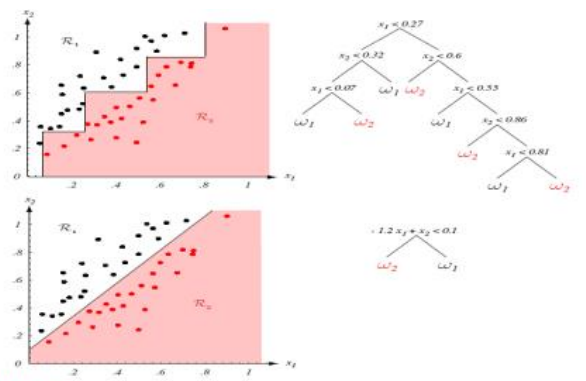
Axis-orthogonal하지 않고, nonlinear하게 split을 할 수도 있다.
이렇게 하면 기존에 수직으로만 split하던 경우의 한계를 극복해서 성능이 높아질 수도 있지만, 결과에 대한 해석력이 떨어질 수 있다.
nonlinear split은 오른쪽 그림과 같이 어느정도 linear한 split으로 대체할 수 있지만, 이런 경우 트리의 크기가 커질 수 있다.
📁 Decision tree Regression
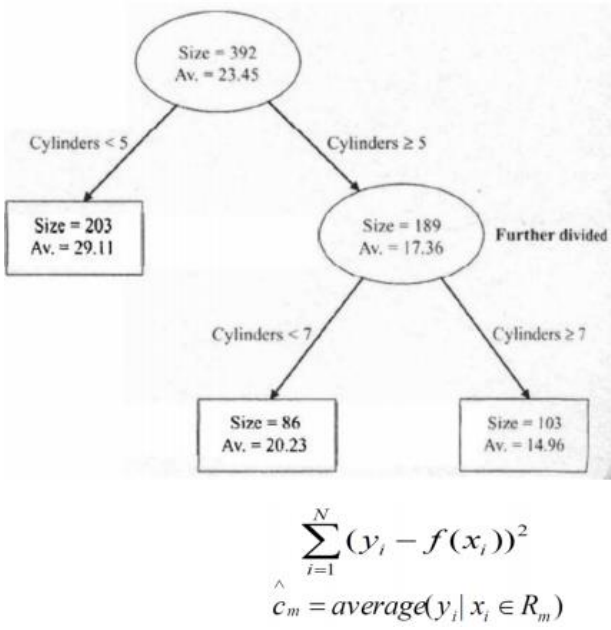
Decision Tree로 classification 외에도 regression 문제를 해결할 수 있다.
불순도를 계산하기보다 리프노드의 값과 실제값의 차이 및 분산과 같은 error를 구함으로써 트리를 구성한다.
📝 정리
Decision Tree는 IF-THEN 룰에 기반한 분류 알고리즘이다.
- 모델을 사용하거나 이해하기 쉽다.
- 해석 및 구현이 쉽다.
- variable selection 및 reduction이 자동으로 이루어진다.
- 통계 모델의 가정이 필요하지 않다.
- missing data를 광범위하게 처리하지 않고도 작업할 수 있다.
- Pruning을 진행한다.
- Greedy 알고리즘과 Axis-orthogonal 방식을 사용함으로써 성능 및 정확도가 낮다.
참고
[데이터마이닝] Decision Tree - How to Split and Best Split
Test Conditions Methods for Expressing Test Conditions 우리는 이전에 split을 하는 기준과 관련해서 이야기했었다. 그래서 자세하게 이야기하기 전에 먼저 attribute type에 대해서 다시 살펴보고 갈 것이다. Bi
velog.io
https://wooono.tistory.com/104
[ML] 의사결정트리(Decision Tree) 란?
의사결정트리(Decision Tree)란? 의사결정트리는 일련의 분류 규칙을 통해 데이터를 분류, 회귀하는 지도 학습 모델 중 하나이며, 결과 모델이 Tree 구조를 가지고 있기 때문에 Decision Tree라는 이름을
wooono.tistory.com



