목차
2023학년도 2학기 충남대학교 조은선 교수님의 컴파일러개론 수업 정리자료입니다.

컴파일러 전반부는 어휘분석, 구문분석, 의미분석, 중간코드 생성으로 나뉜다.
구문분석까지 진행하고, 중간코드를 생성하기 전에 프로그램이 semantics를 분석해두기 위한 의미분석
program semantics에는 두가지 종류가있다.
1. run time에 어떻게 동작하는지에 대한 얘기
2. 프로그램을 돌리지 않고 읽어봤을때 분석.
static semantics는 거의 타입분석과 비슷하다고 할 수 있음.
의미분석 단계에서는 static semantics를 대상으로 진행된다.
symbol tables, types에 대해 알아보자.
📁 Semantic Analasis

semantics analysis는 정석적인 분석 과정이라기보다, 프로그램의 변수, 객체, 식, 문장 등이 제대로 사용됐는지를 미리 확인하는 과정을 말하며, 주로 타입 오류를 판단하거나 변수 scope을 확인해준다.
- Scope 확인 : 변수가 선언되기 전에 사용되었나? 정의가 여러번 되었나?
- Type 확인 : 변수가 할당되는 값과 타입이 일치하는가?
- Contorl flow errors 잡기 : break나 continue가 while이나 for 속에 들어있는지? goto label들이 해당 함수 안에 있는지? 등 AST를 따라가면 어렵지 않게 알 수 있는 간단한 결과들
🌱 Scope
식별자(Identifiers) : 변수, 상수, 함수이름, goto의 타겟이되는 lable 등이 있다. 식별자가 유효한 영역이 존재한다.
그 영역을 scope라고 부른다. 예를 들어 함수 내에 선언된 로컬 변수의 scope은 그 함수이다.
라이프타임과 scope는 완전히 다른 개념. 예를 들어 로컬변수의 경우 lifetime은 함수 호출 시 로컬변수의 자리가 확보되고 함수라 리턴되면 사라진다. 그런데 변수 x를 함수 내에서 선언햇는데 그 함수 내에서만 변수x가 보인다에 초점을 맞추면 그건 scope.
Lexical Scope : 프로그램을 문자적으로(textual)하게 볼 때의 특정 범위를 말한다. 예를들어 코드 몇번째줄부터 몇번째줄까지~ 이런식으로 표현할 수 있는 영역.
보통 문장 block, 형식인자 리스트, 함수 정의문, 소스파일, 프로그램 전체 등을 Lexical Scope의 대상.
식별자 scope의 예시
문장 block 내의 로컬변수 : for 문 내의 int i
함수 내의 로컬변수
함수 내의 형식 인자
소스파일 내의 글로벌 변수
전체 프로그램 내의 extern 변수


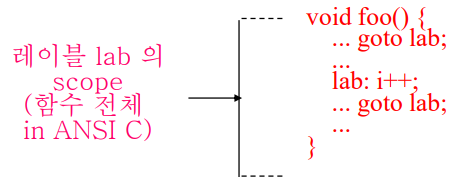
ANSI C의 표준에 따르면, goto 함수와 해당하는 label은 같은 함수 내에 존재해야한다. 즉 label의 scope는 해당 label이 존재하는 함수 전체이다.
가장 중요한 법칙은 각 식별자는 자신의 scope 내에서 한번만 선언돼야한다는 것이다.
field나 method의 scope를 파악하는 방법? 이뭐임?
🌱 Symbol Tables
scope나 타입 정보를 실제로 사용하기 위해서는 어딘가에 저장해둬야함. 이걸 위해 사용하는게 symbol table.
symbol table에는 선언되었을때의 정보, 예를 들어 타입같은 정보가 들어감.
어떤 변수가 리턴되거나 함수의 인자로 들어가는 등 사용될 때는 테이블을 참조해서 올바른 사용인지 확인한다.
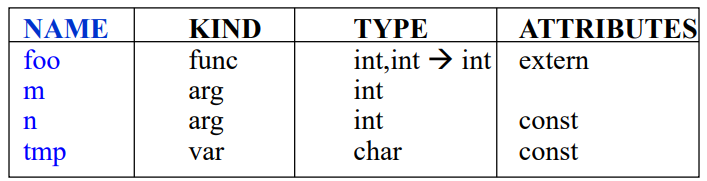
위 테이블은 symbol table의 예시이다.
이런 모양의 자료구조를 갖는다.
NAME : 식별자의 이름
KIND : 함수인지, 인자인지, 변수인지 등을 저장.
TYPE : 식별자가 선언될 때의 타입. int와 int를 받아서 int로 가는 함수의 타입 정의는 이렇게 화살표로함.
ATTRIBUTES : 추가적인 속성
class X {
int X;
int X(int X) {
X: ...
goto X;
...
예를 들어 모든 식별자를 X라고 하면, 이걸 허용하는 언어가 있고 오류가 나는 언어가 있음. 이걸 허용하는 언어는 KIND 필드에서 구분하는것. 자바의 경우 클래스 이름과 메소드이름이 같으면 안됨. 생성자여야만 이름이 동일. 필드이름하고 인자이름은 같을수도 있음. 그럴땐 필드이름을 보통 this.으로 구분.
Symbol Table에서 Scope 정보를 보자.
int x;
void f(int m) {
float x, y;
...
{int i, j; ....; }
{int x; l: ...; }
}
int g(int n) {
char t;
... ;
}
컴파일하는동안 symbol table을 유지하면서 타입 정보를 넣었다가 사용할텐데, 그러면 symbol table을 사용할 때 필요한 자료구조를 생각해봐야함.
1. 한 lexical scope, block, 함수, 파일마다 small table을 만듬.
2. 각각의 scope들이 계층구조를 이룬다.
예를 들어 int i, j가 가지는 중괄호 scope가 있고, 그 바깥에 float x, y를 담고있는 f 함수가 있음. 즉 nesting 되어있음.
만약 5번줄의 ....부분에 변수 x를 참조한다고 하면, 본인 안의 scope에 있는지 확인하고, 본인 밖의 scope에 있는지 확인함. 즉 nesting되어있는 두 scope는 계층구조를 이룬다고 볼 수 있음.
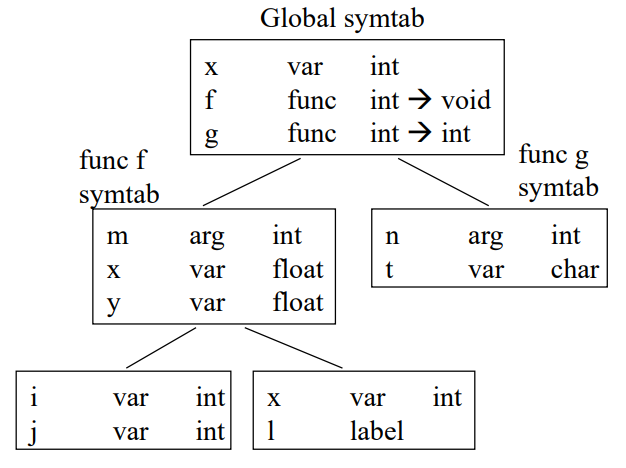
위 코드를 바탕으로 이와 같은 symbol table을 만들 수 있음.
각 scope마다의 small table이 하나씩 존재하고, 그 scope table은 계층구조를 갖고있다.
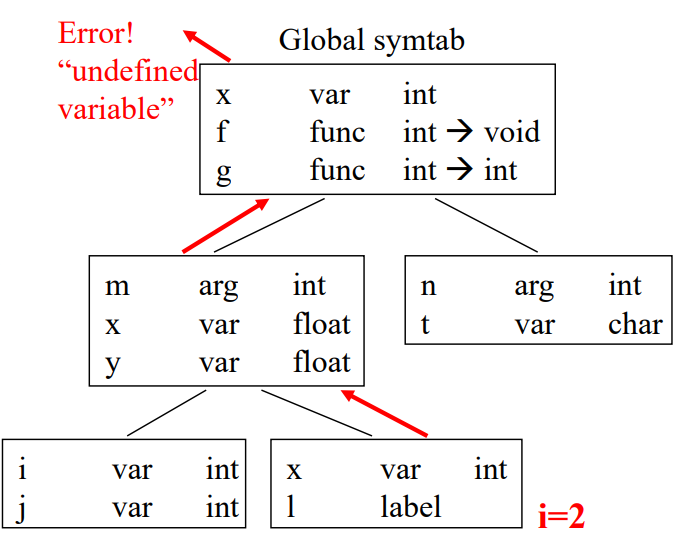
int x;
void f(int m) {
float x, y;
...
{int i, j; x=1; }
{int x; l: i=2; }
}
int g(int n) {
char t;
x=3;
}
만약 예를 들어 위와 같이 코드를 수정했다고 하자. 이때 6번줄의 i=2를 보자. i에 대한 정보를 현재 scope부터 시작해서 한 계층씩 올라가면서 찾는데, 만약 끝까지 없으면 정의되지 않은 변수로 취급하고 에러를 낸다.
본인의 scope만 확인하고 없으면 바로 오류를 내는게 아니다.
📁 Symbol Table Implementation
Symbol Table을 구현해보자.
Symbol Table을 구현할 때 필요한 연산자는 삽입과 검색이 있다.
삽입과 검색하는 point는 구문분석 후 AST까지 모두 만든 후라고 가정한다.
기본적으로 Local하게는 Hash Table을 이용하고, Global하게는 Tree 구조를 사용한다.
계층 구조를 사용하므로.
테이블 entry에서 식별자의 이름은 사실 이름이 그대로 들어가지 않고, 이름들의 string 값을 따로 보관하는 pool이 있어서 거길 pointing하는 구조.
global하게 tree 구조를 사용하지만, 포인터 유지 등의 비용이 발생하는 등 트리의 여러가지 부담때문에 사용의 locailty 성질을 이용해서 다른 자료구조를 사용함.
🌱 Local Hash Table
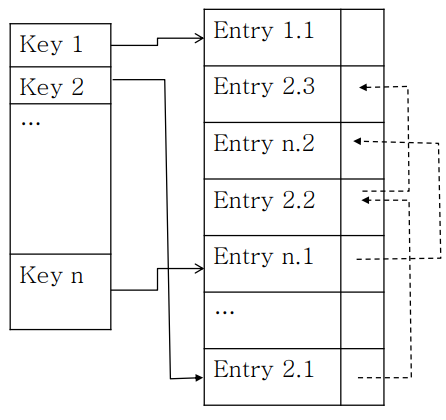
Key값을 해쉬값을 찾았으면, 거기에 해당하는 Value를 찾. 근데 만약에 2번쓰는게 많으면 그니까 같은 해쉬값이 많으면 value 테이블 내의 화살표로 이동하면서 원하는 값을 찾고, 끝까지 찾앗는데 없으면 없음. 해쉬 충돌이 나기 쉽기 때문에 링크드 리스트형태로 같은 해쉬값을 갖는걸 묶어놓는데, 별도의 메모리 공간에 넣지 않고 테이블 내에. 엔트리를 위한 메모리 영역 내에 빈공간이 많아서 그 공간 안에 링크드리스트로 엮어서 들어감.
해쉬가 O(1) 시간복잡도를 가짐. 충돌만 없다면 제일 빠름.
🌱 Global Table Hierarchy
int x;
void f(int m) {
float x, y;
...
{int i, j; ....; }
{int x; l: ...; }
}
int g(int n) {
char t;
... ;
}
계층 구조를 이룸. 트리를 만들 수 있음.
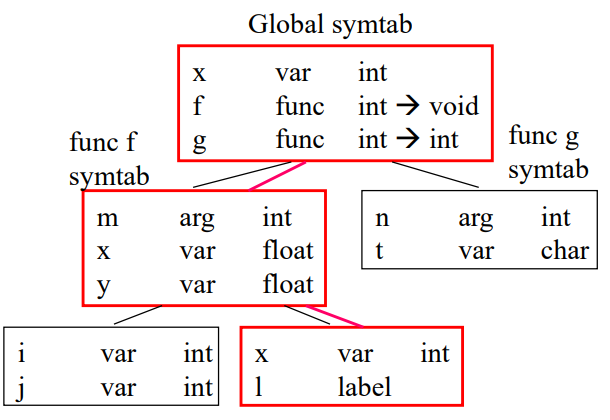
알고보면 스택 구조로 충분해서 골치아픈 트리 구조는 잘 안씀.
int x; 부분을 만나자마자 먼저 global symbol table을 만들고, x를 넣어줌. 그리고 void f를 만나면 f를 넣어줌.
아직 보면 global symbol table에 g가 없음. 코드를 한줄한줄 실행하면서 보기때문에 g까지 아직 못봤음.
다음으로 f 내부를 처리하는게 func f symbol table. 먼저 인자 넣어주고 로컬변수 x, y넣어주고.
다음으로 int i, j에 대한걸 만들고 넣어줌.
이 다으메 int i j에 대한 내용은 블럭을 빠져나간 이후 더이상 필요없어짐. 그러면 int x; l:~ 쪽으로 와서 이 테이블을 만들어줌. 그러면 블록을 빠져나가는 순간 int i, j 테이블을 아예 삭제해버리면됨. 그다음에 int x; l: ~쪽 블록도 빠져나가면 테이블 삭제하고, f 함수 빠져나가면 이 테이블도 삭제하면됨.
만약 g 안에서 f를 호출하면 어쩌지? 괜춘. f 함수는 글로벌 심볼테이블에 잇으니까.
이걸 트리가 아니라 스택구조로 표현할 수 있음.

🌱 Local Table의 계층
int x,y;
char name;
void m1(int ind) {
int x;
}
void m2 (int j) {
{
int f[j];
char test;
}
}
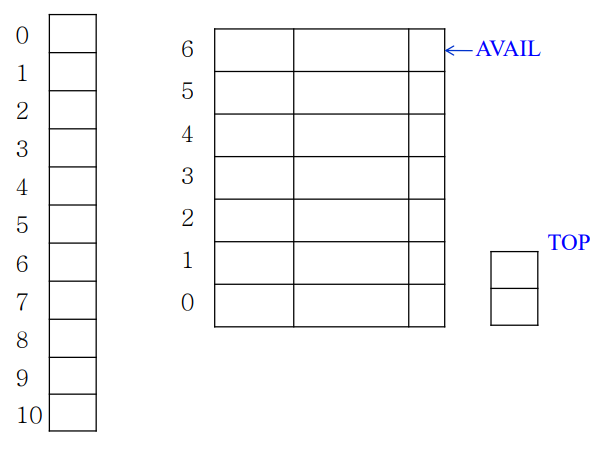
스택에 해쉬테이블을 푸쉬하는 방법, 그리고 각 앤트리가 해쉬테이블. 이 두개를 잘 merge해서 하나의 자료구조로 만든걸 보자.
• x, m1은 1 • name은 2 • ind, j는 4 • test는 6 • f, y는 7 • m2는 10
위 자료가 각 식별자의 해쉬값을 가정한거.

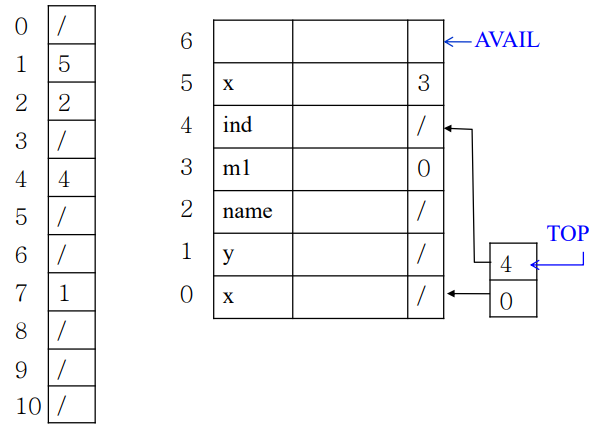
가장 먼저 int x, y부분을 보자.
먼저 왼쪽 해쉬 테이블에 x의 해쉬값인 1번 칸에 x의 entry를 넣는다. 첫번째니까 0번을 넣고, 옆에 테이블 0번에 x를 넣는다. y도 똑같이 해쉬값이 7이니까 7번칸에 1을 넣고, 오른쪽 테이블 1번에 y를 넣는다. char name도 똑같이 2번에 2번.
다음으로 m1을 3번 엔트리에 넣고, 근데 해쉬값이 1임. 1번이랑 연결돼야하니까, 기존의 1번칸에 적혀있던 0을 지우고 3을 넣고, 3 엔트리 옆에 0번을 적는다. 1번 칸에 와서 3번을 먼저 해당하고, 원하는 정보가 x였으면 0번칸으로 내려가라는 의미.
화살표로 가르키고 있는 부분에서 글로벌 변수 x를 접근할 수 없는 게 자연스럽게 구현되고있음. 저기서 x를 찾으면 무조건 5번 엔트리가 구해질테니까.
stack top은 스택의 top 프레임의 시작부분을 나타내는거.

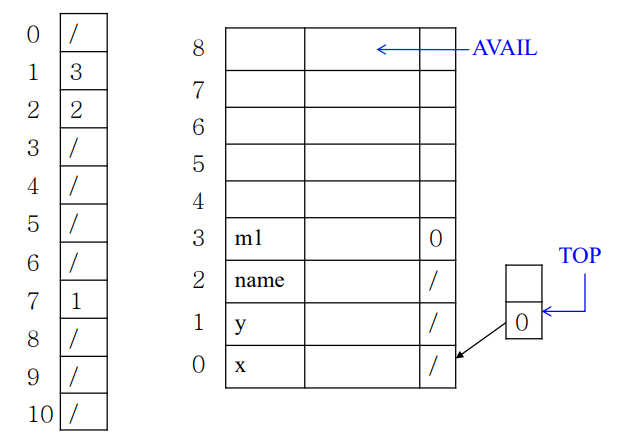
이후 m1 메소드가 끝났으므로 스택에서 m1 내부 scope 부분을 pop 하고, 오른쪽 테이블에서도 지움.

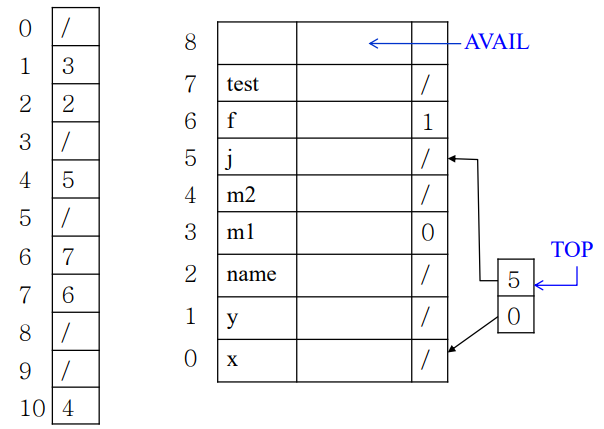
📝 문제 풀어보기
int x;
void f(int m) {
float x, y;
...
{int i, j; x=1; }
{int x; l: x=2; }
}
int g(int n) {
char t;
x=3;
}
1. symbol table을 만들어보자.
2. 각 x 의 assignment 가 어느 symbol table을 참조하는가?
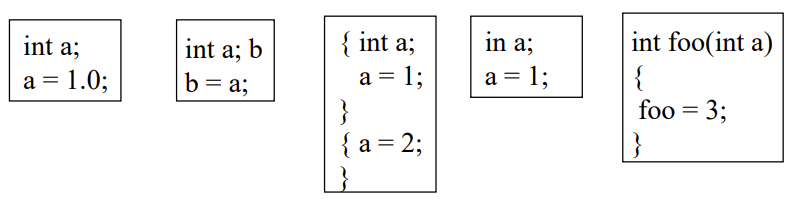
다음에서 오류가 발생된다면 어휘분석, 구문분석, 의미분석 중 어디쯤 속하는지 생각해보시오.


