목차

wji의 편미분.
업데이트 해야하는 웨이트들이 보통 파라미터의 수로 얘기함.
모든 파라미터에 대해 저런 연산을 다 거치는거임. 그래서 연산량이 엄청 많겠지만 모델의 표현력이 올라가고 overfitting문제가 생김.
모델의 구조 자체에서 overfitting을 막을 수 있는 등의 기법이 많이 나오고 있음.
러닝레이트에 따라 수렴하는 속도나 수렴 뭐쩌고가 정해질수 잇음.
적절한 러닝레이트는 웨이트의 초기값에서 적절히 도달하지만
너무크면 계속 발산하는 형태.
너무 작으면 학습속도가 엄청 더딤.
그래서 학습 속도에 따라 러닝레이트를 키우거나 줄여도 됨.
이런 로스펑션이 있는데, 초기값 위치에 따라 local optimal이 무엇이냐에 따라 global을 못찾을수도. 근데 이건 그래디언트 디센트의 한계.
근데 논컨벡스 형태의 함수에서는 방법 자체가 없음. 그래서 방법자체의 문제는 아님.
10 Deep Neural Networks
히든 레이어를 많이 두기 때문에 딥.
더 많은 최적화 업데이트 대상이 되는 파라미터를 많이 두고 더 복잡한 형태로 모델링하는것이 목적.
딥 뉴럴 기반이 딥 네트 머?
높은 capacity를 가지기 위함.
복잡한 관계를 더 잘 표현하기 위함.
nonlinear한 관계 표현 가능. uat. 이것만으로는 충분하지 않은 이유가 복잡한 관계를 표현하지 못하기 때문이 아니라 효율성을 더 추구하기 때문.
generaliztion 효과가 더 뛰어남.
여러층을 쌓을때의 문제점.
1. 배니싱 그래디언트
각각의 웨이트에 대한 편미분을 계산하다보면 수많은 그래디언트를 계속 곱해줘야함. 그러다보니 계속 곱하다보면 초기의 웨이트들은 그래디언트가 거의 0이 됨. 점점 줄어들음. 그러다보니 앞의 웨이트에 대한 학습이 제대로 안됨.
이걸 해결하고자 히든 노드에 activatie funcction을 시그모이드가 아니라 ReLU function을 두자.
시그모이드는 기울기가 0에 가까운 부분이 너무 많이 존재.기울기가 제일 큰 부분도 기울기가 1이 안됨. 한 0.24 이럼. 시그모이드를 쓰면 계쏙 0.24보다 작은 값이 계속 곱해지는거임. 곱하면 곱할수록 그래디언트가 작아짐.
그래서 음수일땐 기울기가 0이고 양수일땐 1인 ReLU를 쓰자. 양수일땐 여러번 곱해도 그래디언트가 작아지지 않음.
2. 층을 여러개 쌓고 노드를 여러개 두다보니까 overfitting 물론 한층에 여러개 노드보단 낫겠지만.
해결하기 위해 regualization 기법 사용. 학습 과정에서 일반적으로 사용하는 방법은 drop out. 특정 노드들 사이의 연결을 끊어주는 방법. 예를 들어 dropout rate가 0.25면 한 층의 노드 4개중에 하나를 끊.
이렇게 되면 구조에 변형을 가질 수 있게 되기 때문에 앙상블의 이점을 얻을 수 있음.
혹은 data augmentation 하나의 데이터더라도 여러가지로 변형하여 사용. 규제와 일반화 성능을 얻을 수 있음. 보통 이미지 처리에서 많이 쓰임. 사진을 자르거나, 노이즈를 섞거나, ...
parameter sharing, sparse conntctin은 뒤에.
3. 웨이트를 업데이트할때, 즉 최적화할때 너무 오래걸림. 개수도 많고 구조도 딥해서 high capacity.
해결 방법중 하나는 SGD. Stochastic Gradient descent. 앞에서 설명한 업데이트 과정은 100개의 데이터가 있다고 치면 x1데이터를 넣어서 예측값을 계산하고 로스를 계산하고 로스로 웨이트를 업데이트 하는 과정을 반복. 실제로는 웨이트 업데이트 방향을 정해줘야함. 모든 걸 보고 한번 업데이트하는게 정확. 지금의 웨이트에 대해 업데이트 하지않고 100개의 데이터를 다 넣어준다음 각각의 로스 100개를 다 계산한 후에 이를 평균내서 평균낸 로스에대해 웨이트를 업데이트. 이게 GD. Stochastic이 들어가면, 이렇게 하면 한 스텝 업데이트할때 시간이 너무 오래걸려서, 업데이트 할때 데이터를 하나만 보고 전체를 업데이트. 정확도는 떨어지겠지만 더 빨라짐. 이때 데이터 몇개를 볼건지 정해주는 방법은 mini-batch GD. 근데 보통 mini-batch GD를 SGD라고 말함. mini-batch가 1인게 이론적으로는 SGD이지만, 그냥 그렇게 부름. 스텝을 갈 때마다 연산량을 줄여주는 방법.
두번째로 adaptive learning rate. 러닝레이트를 너무 크지도 작지도 않게 적당히 둬야함. 학습 과정에서 레이트를 계속 조절해주는 방법. 누적 벡터를 계산해서, 계속 같은 방향으로 가고 있으면 최적의 값으로 수렴중이라고 판단하고 레이트를 키워줌. 어느정도 수렴하면 레이트를 작게해줌. 스텝의 크기를 조절해주는 방법.
momentum. 관성. 최적의 값으로 가지 않고 들쭉날쭉한 성질이다보니, 관성이 있따고 가정. 이전에 갔던 방향으로의 관성이 있다고 가정하는거임. 그 관성을 같이 더해서 그 다음 스텝을 정해줌. 스텝의 방향을 조절해주는 방법.
adam : adaptive 방법이랑 momentum방법 둘다 쓴거임. 가장 일반적으로 쓰는방법.
input과 output 사이의 관계, 함수를 최적의 함수를 근사하는게 최종 목표.
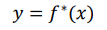
이런 최적의 함수가 잇다고하자. 우리는 얘를 모방하고자 하는거.
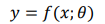
파라미터간의 출력값을 내도록.
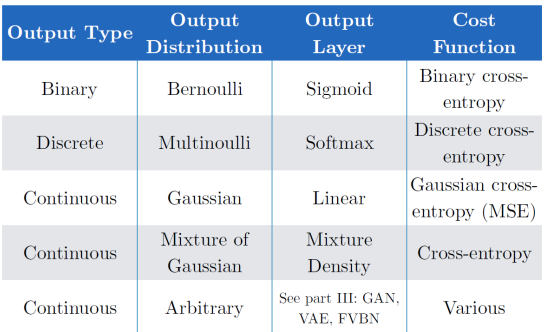
아웃풋 노드. 출력하고자 하는 형태나 학습하고자 하는 데이터에 따라 function을 정해줄 수 있음.
hidden node에서 ReLU가 가장 우수함. 장점은 계산하기 쉽고 편미분 계산할때도 쉬움. 미분 값 자체가 큼. 시그모이드는 최대 0.24 0.25밖에 안되잖아. 단점은 음수 영역에서 activatoin 출력이 0이 됨. backpropagation 과정에서 웨이트에 업데이트가 제대로 진행되지 않을 수 있음. 그래도 여전히 많이 쓰이는 이유는 저게 0이 되는게 노드랑 레이어가 많으면 큰 문제가 되지 않음. 보통 ReLU 표시할때 max(0, x)라고 표시함. y=0과 y=x 함수 두개가 합쳐진 모습이니까. 그래서 만약에 좀 형태를 바꿔서 y=x랑 y=0.1x의 합으로 나타내고 막 이럴수도 있음. 이게 generalized ReLU. 그래서 0.1 자리를 알파로 두고 여기를 학습하자고 하는게 Parameter ReLU
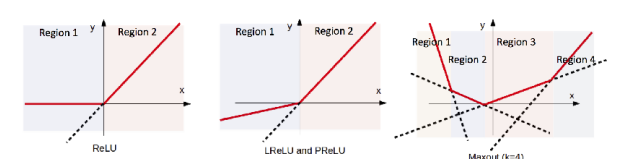
요새 ReLU, LReLU를 많이 쓰는 이유가 장점이 너무 좋아서. 연산량이 적음 (절대적인 연산량이 작은건아니지만)
# CNN
이미지 처리에 특화된 모델. 컨볼루션을 연산에 활용.
이미지에서는 각 feature가 픽셀의 값. h * w * d. input의 크기가 엄청 커짐. 얘를 어떻게 효과적으로 처리할 수 있을까 ?
sparse connection. fully-connected network
필터의 개수는 = (i-1) 채널의 수 * i 채널의 수
필터 값의 개수 = (i-1) 채널의 수 * i 채널의 수 * 가로 * 세로



