목차
2023학년도 2학기 충남대학교 이영석 교수님의 컴퓨터네트워크 수업 정리자료입니다.
📁 네트워크 계층
데이터 링크 계층에서는 같은 네트워크 상에 있는 컴퓨터끼리 데이터를 전송한다. 같은 네트워크 상의 컴퓨터는 길찾기 알고리즘 상에서는 '인접한 노드'이므로, 즉 인접한 노드 사이의 데이터를 전송할 수 있는 것이다.
인접하지 않은 노드인 '다른 네트워크 혹은 인터넷 상의 컴퓨터' 사이에서 데이터를 전송하는 기능은 네트워크 계층의 역할이다.
네트워크 계층은 송신 호스트에서 수신 호스트로 세그먼트를 전송하는 포워딩(Forwarding) 기능과, 송신 호스트로부터 수신 호스트까지의 노드 간의 길을 찾고 알려주는 라우팅(Routing) 기능을 수행한다.
1. forwarding
- 라우터의 input 포트에서 output 포트로 패킷을 옮기는 기능.
- 하드웨어 영역인 data plane의 영역에서 진행된다.
2. routing
- 목적지까지 패킷을 전달하는 경로를 결정하는 기능
- 소프트웨어 영역인 control plane의 영역에서 진행된다.
🌱 Data Plane과 Control Plane
data plane 과 control plane은 네트워크 계층을 두 계층으로 나눈 것과 같다.
data plane은 라우터마다 local하게 존재하는 function이다.
라우터같은 네트워크 장비는 데이터를 전송하는 forwarding 기능을 수행하는데, 데이터 전송은 보통 하드웨어가 수행한다. 해당 기능을 수행하는 게 data plane이라는 영역이다.
또한, 데이터를 어떻게 전송하는지 길을 찾는 routing 기능을 수행하는데, 이는 길찾기 알고리즘과 같이 소프트웨어가 수행한다. 이 전반적인 기능 수행 부분을 control plane이라고 말한다.
이때 control plane을 구현하는 두 가지 방법이 있다.
1. Per-router Control Plane
전통적인 라우터 알고리즘으로, 모든 라우터 내에서 각각의 forwarding과 routing을 모두 수행한다. 모든 라우터가 자신이 가진 라우팅 알고리즘을 수행하여 routing table을 구성한 후 이를 토대로 forwarding을 수행하는 것이다.
모든 라우터가 control plane과 data plane을 갖고 있다.
각각의 라우터가 개별적으로 라우팅 알고리즘을 돌리면서 서로 정보를 주고받는다.
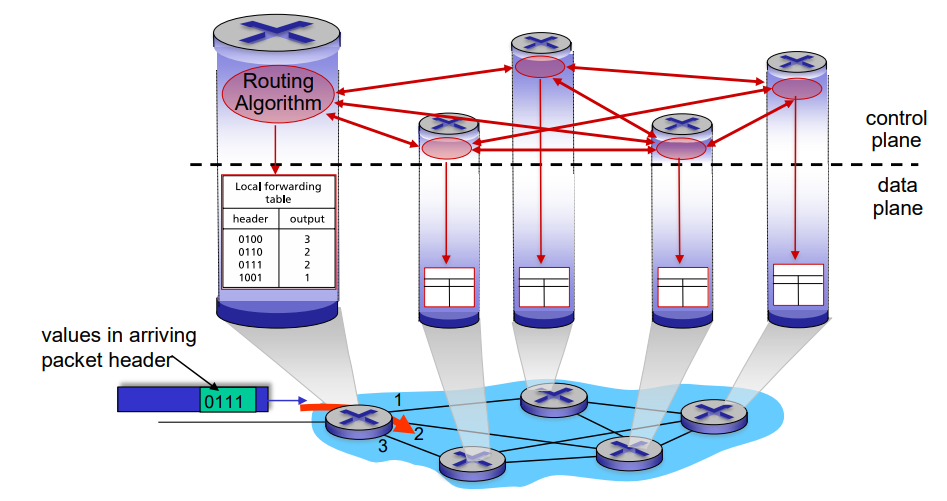
그런데 forwarding은 하드웨어 영역에서 발생하여 nanosecond 단위가 소모되는 반면, routing은 소프트웨어 영역에서 발생하여 millisecend 단위가 소모된다. 또한 시간이 지나면서 control plane 영역이 굉장히 복잡해졌다.
또한 라우터끼리 통신하므로 라우터 사이의 connection에 문제가 생기면 정보가 원활하게 전달되지 않을 수 있다.
따라서 오버헤드가 큰 routing을 따로 분리해서 원격 서버(remote server)에서 관리하는 방식이 SDN이다.
2. SDN(Software-Defined Network)
기존의 방식은 각각의 라우터마다 control plane이 존재했으나, 외부에 서버를 두어 그곳으로 통합시키고 각 라우터는 data plane 영역의 기능인 데이터 전송 역할만 수행한다.
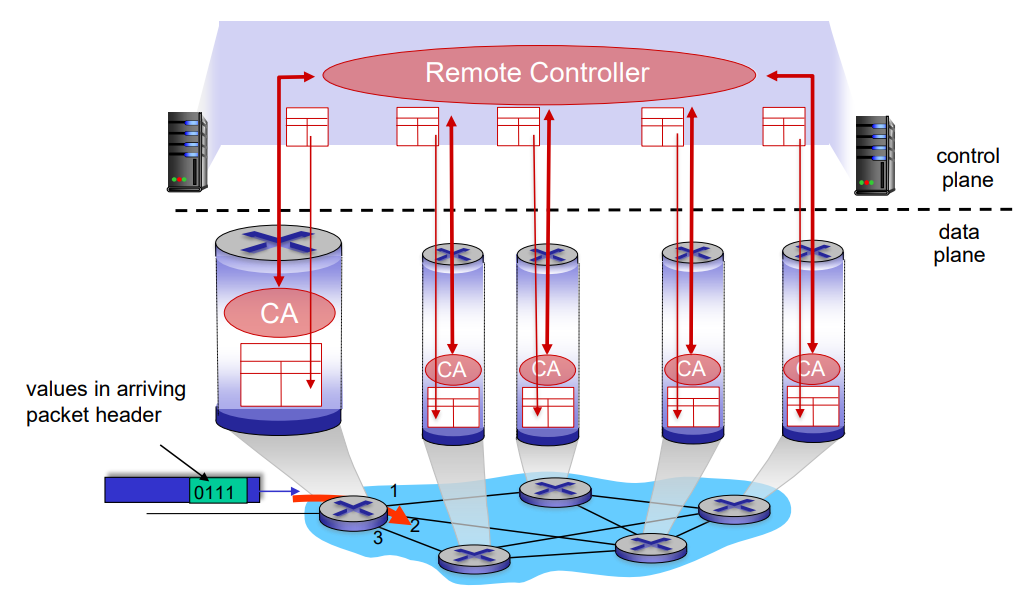
위 그림에서 Remote Controller가 routing을 분리해둔 원격 서버이다. 이 remote contoller가 각각의 라우터 별로 내장된 local Control Agent(CA)와 상호작용한다.
remote controller는 각 라우터의 CA로부터 정보를 받아서 routing algorithm을 수행한 후 flow table을 제작한다. 이 flow table을 각 라우터에게 전달하면 라우터는 해당 테이블을 토대로 forwarding을 진행한다.
📁 Routing Protocol
routing을 수행하기 위해서, router 혹은 remote controller는 라우팅 테이블을 계산해야한다. 이때 이 라우팅 테이블을 생성, 유지, 업데이트, 전달하는 프로토콜을 라우팅 프로토콜이라고 한다.
즉 라우팅 프로토콜의 목표는, 정보가 목적지까지 이동할 때 어떤 라우터를 어떤 순서로 거쳐야하는지 최적의 경로를 계산하는 것이다. 라우팅 프로토콜에서 라우팅 테이블을 구성하기 위해 경로를 찾는 알고리즘을 수행해야하는데, 이때 수행되는 알고리즘의 종류에 따라, 혹은 라우팅 테이블 구성하는 방법에 따라 프로토콜을 구분할 수 있다.

글로벌은 link state와 같이 모든 라우터가 네트워크 전체 topology와 link cost를 알고있는 경우이며, 분산형은 DV와 같이 라우터가 물리적으로 연결된 이웃의 cost만 알고 있고 이웃의 정보를 받아 조금씩 업데이트하는 경우를 말한다.
🌱 라우팅의 유형
1. Static routing(정적 라우팅)
라우팅 테이블에 경로를 수동으로 추가해야하는 프로세스를 말하며, 시간에 따른 경로 변경이 느리다.
2. Dynamic routing(동적 라우팅)
라우팅 테이블에서 경로의 현재 상태에 따라 자동으로 경로를 조정한다. 시간에 따라 주기적으로 빠르게 link cost가 업데이트된다. RIP, OSPF와 같은 프로토콜이 있다.
일반적으로 distance vector 알고리즘은 RIP와 같은 프로토콜에 사용되고, Link-state 알고리즘은 OSPF와 같은 프로토콜에 사용된다. 두 알고리즘은 일반적으로 dynamic routing을 위해 사용되지만, static routing을 위해 사용할 수도 있다.
📁 Routing Algorithm
라우팅 알고리즘에는 두가지 종류가 있다.
1. Distance Vector(DV)
경로를 결정할 때 통과해야하는 라우터의 수가 적은 쪽으로 경로를 결정하는 방법이며, DV 방식을 사용하는 프로토콜에는 RIP가 있다.
대표적으로 벨만포드 알고리즘이 DV 방식을 사용하는 알고리즘이다.

벨만포드 알고리즘의 기본 정의는 x에서 y로 가는 최소 비용 Dx(y)는 "x와 이웃한 모든 정점 v에서 y로 가는 최소 비용 + x에서 v로 가는 최소 비용"의 값이다.
벨만포드로 계산하는 예시로는 아래와 같은 경우가 있다.

벨만포드 알고리즘을 이용하여, Distance Vector 알고리즘은 다음과 같은 방식으로 수행된다.
- 각 라우터는 지금까지 추정된 최소 비용 경로인 본인의 Distance Vector를 가지고 있다.
- 각 노드가 자신의 link state를 모니터링하면서, 본인의 DV가 바뀌면 이웃에게 알린다.
- 라우터는 받은 DV를 반영하여 벨만포드 알고리즘으로 본인의 DV를 업데이트한다.
즉, 현재 라우터가 x, 이웃 라우터가 v, 목적지 라우터가 y라고 할 때, x부터 v까지의 경로와 v로부터 받은 DV의 합이 가장 작은 v를 선정하여 업데이트하는 것이다. - 1-3을 계속 반복하면 추정된 최소 비용 경로는 실제 최소 비용 경로에 수렴하게 된다.
distance vector는 반복적으로 cost가 변화한다는 점에서 iterative하다는 특징이 있고, 이웃 라우터의 DV에 변화가 생길때까지 기다렸다가, 변화가 일어나면 다시 계산해야한다는 점에서 asynchronous하며, 각 노드가 DV가 바뀔때만 알려서 모두가 업데이트되지 않는다는 점에서 distributed 및 self-stopping이라는 특징이 있다.
예를 들어 distance vector를 계산해보자.
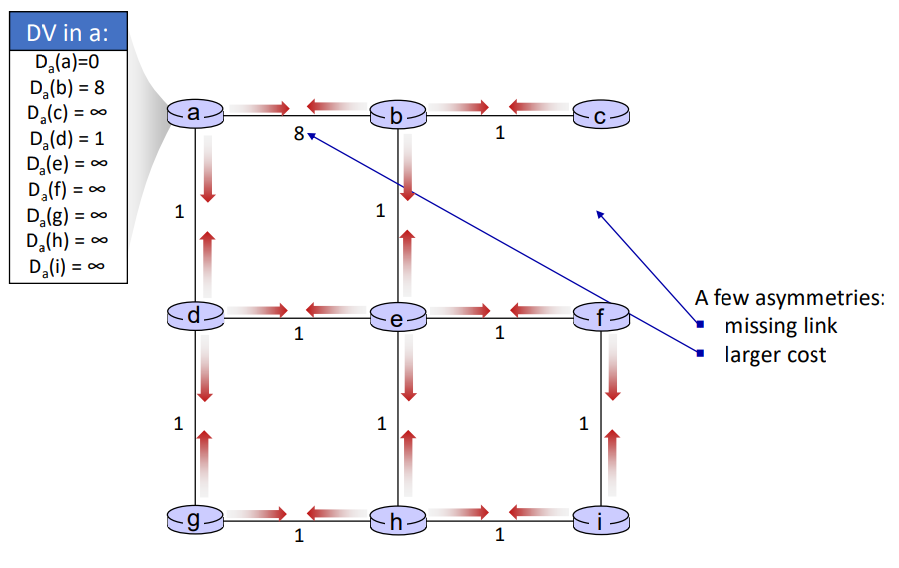
가장 처음 상태는 모든 노드가 자신에게서부터 나가는 링크에 대한 정보만 갖고있다. 라우터 a라고 가정하면, 자신의 DV는 0, b의 DV는 8, d의 DV는 1이고, 나머지 라우터들에 대한 DV는 무한대로 설정해둔다. 이때를 t = 0이라고 가정하자.
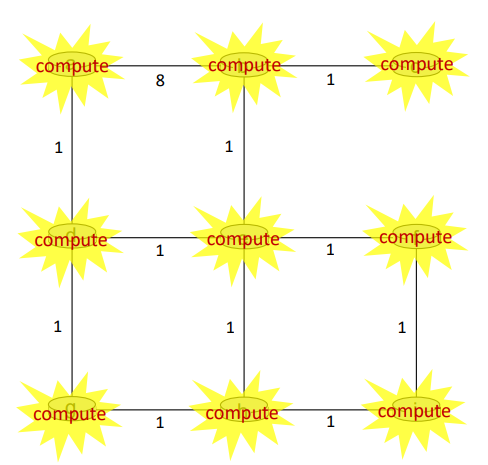
모든 노드들이 이웃에게 본인의 DV를 전달한 이후 t = 1이 되었다. DV를 전달받은 노드들은 본인의 DV를 다시 계산하고, 이렇게 업데이트된 본인의 새 DV를 다시 이웃에게 전달한다.
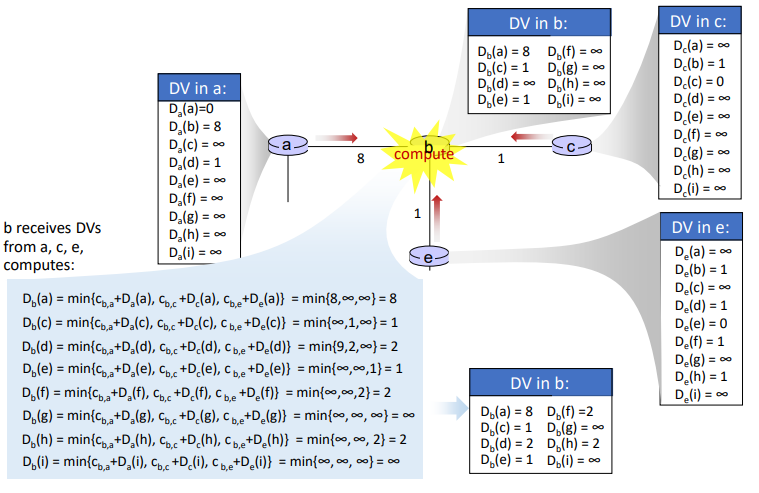
예를 들어 라우터 b의 경우 a, c, e로부터 DV를 전달받아 상단 표와 같은 상태가 되었고, 이를 반영해 DV를 재계산한 결과 하단 표와 같이 distance table을 업데이트할 수 있다.
이후 t = 2가되어 모든 노드들이 다시 전달받은 DV를 이용하여 본인의 DV를 업데이트하고, 이를 이웃에게 전달한다. 이 과정을 DV의 변화가 없을때까지 계속 반복한다.
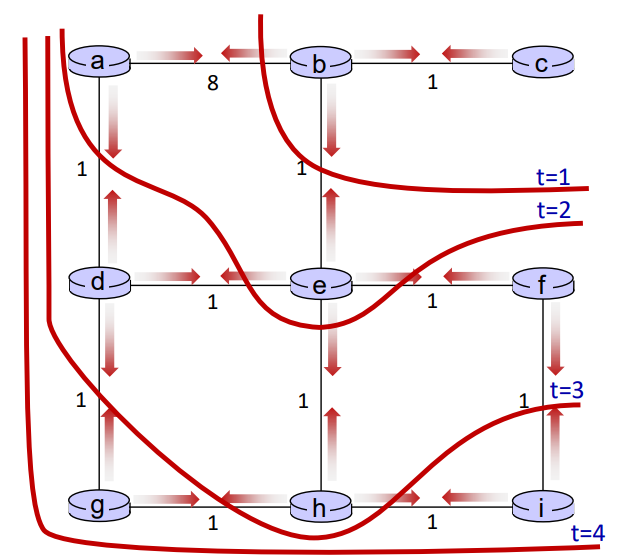
위에서 계산할 때 변수 t로 사이클 수를 계산했는데, 이 t는 곧 어떤 라우터가 DV를 반영한 라우터가 얼마나 떨어져있는지를 나타낸다.
예를 들어 t = 0일때, 라우터 c의 DV는 0으로 아무런 이웃의 DV도 반영하지 않았다.
t = 1일때, c와 한 칸 떨어져있는 b의 DV를 전달받고 반영하여 본인의 DV가 업데이트되었다.
t = 2일때, b가 t =1에서 계산할 때 a와 e를 전달받아 계산하였으므로, c는 두 칸 떨어져있는 a와 e, 그리고 한 칸 떨어져있는 b까지 반영한 DV 테이블을을 얻는다.
Count-to-infinity problem
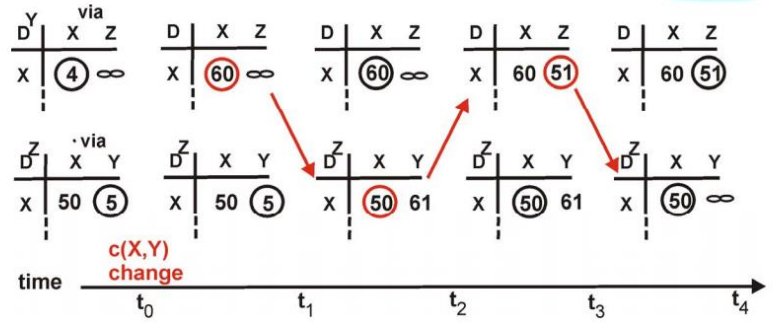
만약 link cost가 바뀌면 어떻게 될까?
라우터가 링크 비용이 바뀐 것을 감지하면, 라우팅 정보를 수정하고 DV를 다시 계산한다. 이렇게 계산했을 때 DV가 변경되었으면 이를 이웃에게 알린다.
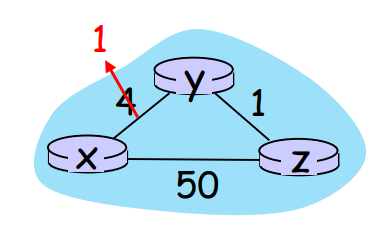
만약 x에서 y로 가는 비용이 4에서 1로 바뀌었다고 하자.
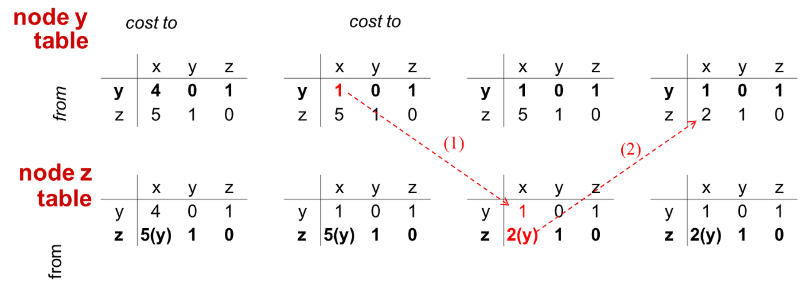
- y가 링크 비용의 변화를 감지하고, 본인의 DV를 업데이트 한 후 이웃에게 알린다.
- z가 y의 새 DV를 전달받고, 본인의 DV를 업데이트한 후 이웃에게 알린다.
- 이후 어떤 라우터의 DV도 변화가 없기 때문에 과정이 종료된다.
링크 비용이 줄어드는 경우 전체 DV의 업데이트도 빠르게 진행되며, 이를 good news travels fast라고 부른다.
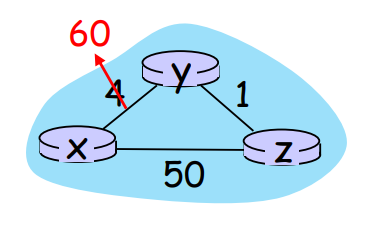
그런데 만약 x에서 y로 가는 비용이 4에서 60으로 올랐다고 하자.
위 과정을 y에서 x로 가는 최소 비용 경로가 51이 될 때까지 반복할 것이다.
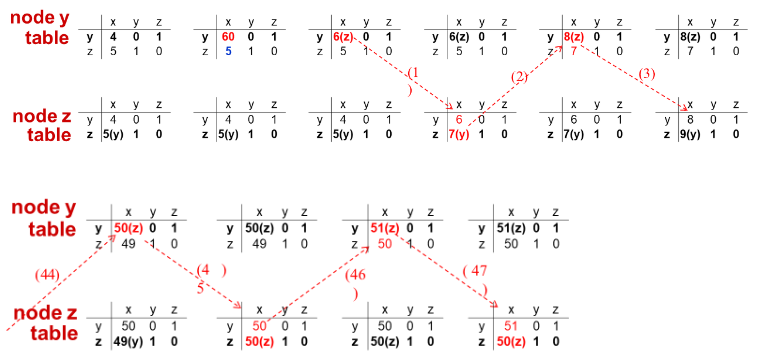
만약 링크 비용이 더 커진다면 참조가 더 많이 발생할 수 있다. 이를 count-to-infinity 문제라고 한다.
이 문제가 발생하는 결정적인 이유는 왔던 경로를 되돌아가기 때문이다. 이를 방지하기 위해 poisoned reverse 방식을 도입한다. 예를 들어 z가 y를 통해서 x로 간다면, z가 y에게 z에서 x로 가는 비용이 무한대라고 알려주는 식이다. 하지만 이 방법을 사용해도 완벽하게 해결해주지는 못한다.
2. Link State
네트워크 대역폭, 지연 정보 등을 종합적으로 고려해서 cost를 산정하고, 해당 링크의 cost에 따라 경로를 결정하는 방법으로, 어떤 하나의 노드부터 다른 모든 노드로 가는 최소 경로를 모두 구하여 그 노드에 대한 forwarding table을 만든다.
Link State 방식을 사용하는 프로토콜에는 OSPF, IS-IS, BGP 등이 있다.
모든 노드가 link state broadcast에 의해 전체 network topology와 링크 비용을 알고있는다는 점에서 centralized 특징을 갖고, 계산을 k번 반복하면 k개의 목적지를 향한 최소비용경로들을 찾을수 있다는 점에서 iterative하다.
대표적으로 다익스트라 알고리즘을 사용한다.
다익스트라 알고리즘을 사용한 link state 과정 및 수도코드는 다음과 같다.
- 시작 노드에서 모든 노드들까지의 거리를 초기값으로 설정한다. 이웃한 노드는 link cost로 설정하고, 이웃하지 않는 노드들은 무한대로 설정한다.
- 현재 N'에 속하지 않는 노드 중 cost가 가장 작은 값을 기준으로 경로를 업데이트한다.
이때 cost는 "기존에 작성되어있던 cost"와, "현재 테이블에 작성되어있는, 선택노드까지의 거리 + 선택노드부터 본인노드까지의 link cost" 중 작은 값으로 업데이트한다. - 업데이트 이후 N'에 해당 노드를 추가하고, N'에 모든 노드가 들어갈때까지 이 과정을 반복한다.
🌙 용어정리
- c(x,y) : 노드 x에서 y로 향하는 직접적인 링크의 비용을 나타내며, x와 y가 이웃하지 않는경우 무한대의 값을 갖는다.
- D(v) : 현재까지 계산한 목적지 v까지의 최소비용 추정치를 나타낸다.
- p(v) : 직전에 지나온 노드
- N' : 현재까지 최소비용경로가 계산된 노드들의 집합

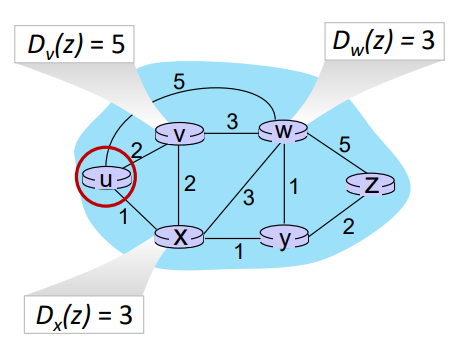
예를 들어보자.
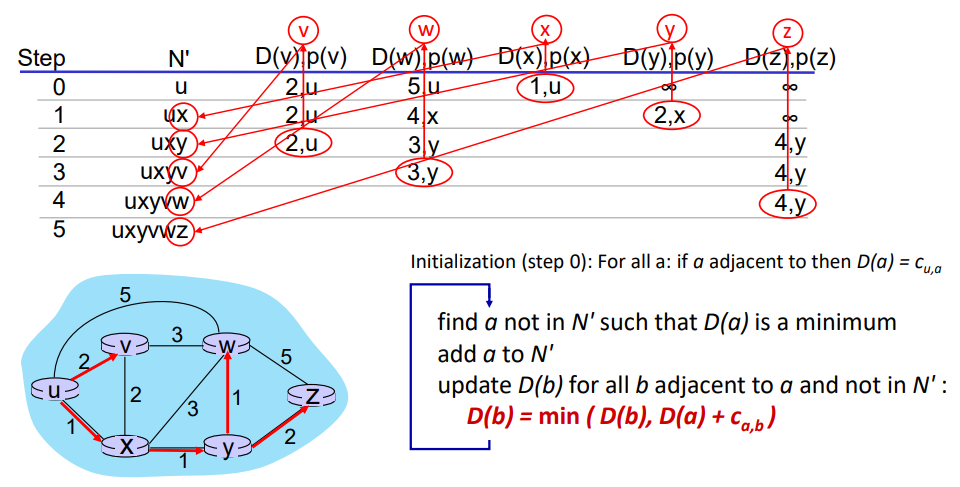
step0. u에서 시작한다고 가정하자. u와 인접한 v, w, x는 cost를 저장하고, 나머지 노드는 현재 정보를 알 수 없기 때문에 최댓값을 저장한다.
step1. N'에 포함되지 않는 노드 중 최소비용을 가지는 노드를 선택하여 N'에 포함시킨다. 현재 x가 1의 최소비용을 갖고 있으므로, N'에 x가 포함되었다.
이후 x와 인접하고 N'에 포함되지 않는 노드 v, w, y의 비용을 수정한다.
예를들어 D(w)를 보자. 기존에 작성되어있는 비용은 5이고, 업데이트하고자 계산한 값은 시작노드 u부터 선택노드 x까지의 현재 추정비용 1 + 선택노드 x부터 본인노드 w까지의 link cost 3 = 4이다. 업데이트하고자 하는 값이 더 작으므로 비용을 4로 업데이트하고, 이때 x를 거치므로 옆에 x라고 기록한다.
step2+. 모든 노드가 N'에 포함될때까지 위 과정을 반복한다.
위 테이블을 통해 u에서 모든 노드까지의 최단거리와 경로를 다음과 같이 구할 수 있다.
- u에서 z까지의 최단거리는 4이고, 최단 경로는 u -> x -> y ->z 이다.
- u에서 w까지의 최단거리는 3이고, 최단 경로는 u -> x -> y ->w 이다.
- u에서 v까지의 최단거리는 2이고, 최단 경로는 u -> v 이다.
- u에서 y까지의 최단거리는 2이고, 최단 경로는 u -> x -> y 이다.
- u에서 x까지의 최단거리는 1이고, 최단 경로는 u -> x 이다.

또다른 예시를 보자.
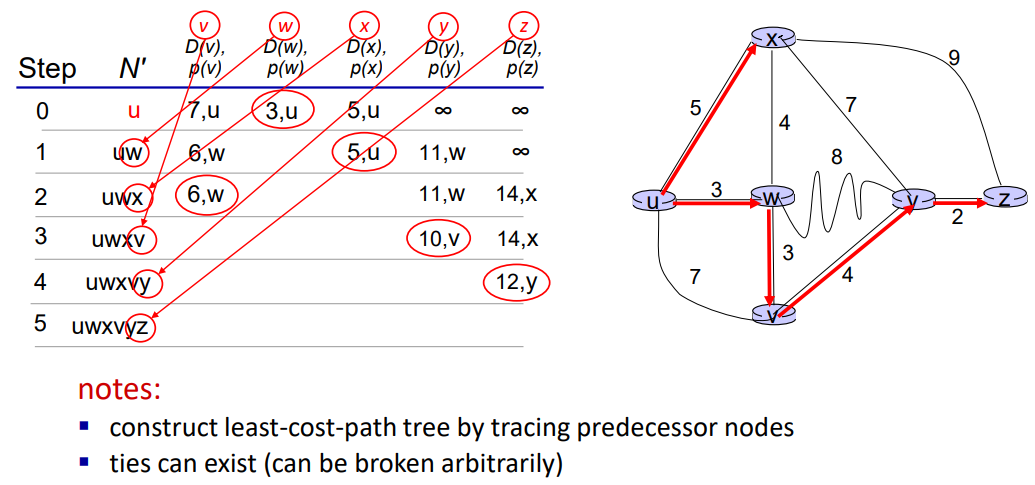
알고리즘의 시간복잡도는 O(n^2)인데, heap과 같은 우선순위큐 자료구조를 활용하면 O(nlogn)도 가능해진다.
또한 각 라우터는 link state 정보를 다른 n개의 라우터에게 broadcast해야하는데, 이 과정에서 효율적인 broadcast 알고리즘을 사용하면 O(n)까지 링크를 교차할 수 있다. 이렇게 각 라우터의 메세지가 O(n)개의 링크를 교차하면, 전체가 모두의 메세지를 받는데에는 O(n^2)이 걸린다.
Route Oscillations
link cost를 네트워크에서 발생하는 트래픽에만 의존하도록 설계하면, 불필요한 반복이 일어나 route가 계속 변동되는 현상인 route oscillation이 발생할 수 있다.
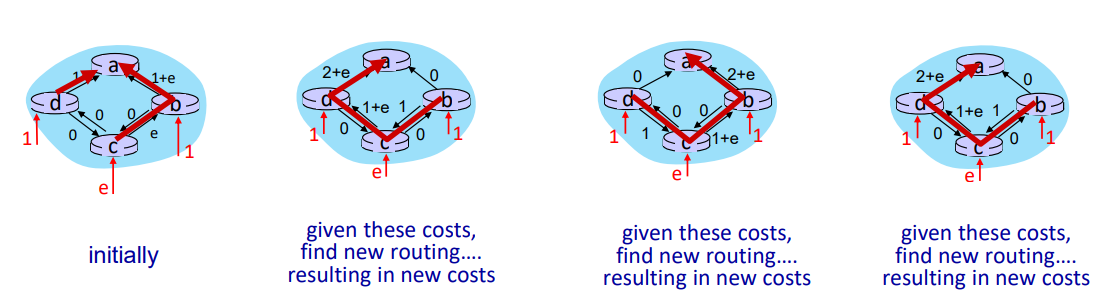
라우터 동기화 시점을 각각 다르게 하거나, DV를 사용하여 해결할 수 있다.
참고
https://harveywoods.tistory.com/35
LS Routing, DV Routing
네트워크 강의를 듣던 중에, 네트워크 계층에 대한 내용을 다루던 중 라우팅 개념에 대한 설명이 스킵된 것 같아 자세히 알아보기 위해 라우팅 프로토콜을 정리해보았다. Routing - 정적 라우팅(Sta
harveywoods.tistory.com
https://velog.io/@seyeop03/Chapter-9-%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EA%B3%84%EC%B8%B5
Chapter 9 네트워크 계층: Data plane
segment를 송신호스트 ⇒ 수신호스트로 전송한다.송신측에서는 segment를 datagram으로 캡슐화하고,(datagram==IP계층의 패킷)수신측에서는 segment를 전송계층으로 옮긴다.network layer은 모든 host, router에서
velog.io
https://east-star.tistory.com/23
네트워크 계층(Network Layer) - Data Plane
네트워크 계층은 어떤 일을 할까요? 바로 옆 노드 통신을 넘어서 최적의 길찾기 역할을 합니다. 메일을 보낼 때 최종 목적지 노드에 도달하려면 어떻게 가야하는지 네비게이션처럼 알려주는 것
east-star.tistory.com
https://velog.io/@dltmdrl1244/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-5-3.-SDN
[네트워크] 5-3. SDN
[네트워크] 5-3. SDN
velog.io
https://m.blog.naver.com/aakim66/222014688951
4-4. Network Layer SDN
1. SDN 1.1 SDN이 나온 배경 - link state 알고리즘이나 distance vector 알고리즘을 사용하게 되면 ...
blog.naver.com
https://nan-noo.tistory.com/22
[전공 시리즈] 4. 라우팅 프로토콜(Routing Protocol)
[전공 시리즈] 3. IP(Internet Protocol) [전공 시리즈] 3(1). IP 주소 체계 [전공 시리즈] 2. 데이터 링크 계층과 인터페이스, ARP(Address Resolution Protocol) [전공 시리즈] 1. 인터넷과 프로토콜, 계층화 원칙 [전
nan-noo.tistory.com
https://velog.io/@cyw320712/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-5-Network-layer-control-plane-1
네트워크 5 - Network layer - control plane (1)
지난 Data plane에 이어서 control plane을 정리해보자 network-layer function에는 forwarding과 routing이 있다고 언급했었다. forwarding을 담당하며, buffer관리 등을 data plane에서 신경쓰며, Rou
velog.io
https://choiblack.tistory.com/33
[Network] Routing algorithms - Distance Vector
이 포스팅은 앞선 Routing Protocols - link state 다음으로 이어진다. 라우팅 알고리즘의 목적 라우팅 알고리즘의 목적은 출발지 라우터에서 목적지 라우터까지 최단 비용으로 갈 수 있는 길을 찾는 것
choiblack.tistory.com



