목차
2023학년도 2학기 충남대학교 김현수 교수님의 소프트웨어공학 수업 정리자료입니다.
📁 아키텍처 설계과정
아키텍처 설계란 시스템의 기능적 요구사항을 구현하는 방법,재정적 제약 등 비기능적 요구사항에 의한 제약을 준수하는 방법, 좋은 품질의 일반적 원칙을 고수하는 방법을 찾기 위한 문제 해결 과정을 말한다.
설계 담당자는 설계 과정에서 작은 문제들에 직면하게 된다. 이러한 이슈들에는 해결책으로서 여러가지 설계 옵션이 존재하고, 설계 담당자는 이슈를 해결하기 위해 선택사항 중 가장 좋은 방안을 찾아 의사결정을 내려야 한다.
이때 설계에 대한 의사결정을 내리기 위해 소프트웨어 엔지니어가 사용할 지식 및 정보의 종류는 다음과 같다.
- 요구사항 정보
- 이전까지 만들어진 설계 작업 정보
- 가용한 기술 정보
- 소프트웨어 설계 원리와 'best practices'정보
- 과거에 잘된 설계 작업 정보
🌱 설계 범위
설계 범위(Design Space)란 서로 다른 대안들을 선택할 수 있는 가능한 모든 설계 방법의 영역을 말한다.
설계 범위를 통해 설계 시 여러가지 경로(대안)을 찾고 의사결정을 내리는 과정을 통해 최종 소프트웨어 산출물을 얻을 수 있다.

🌱 설계 용어
1. 컴포넌트
컴포넌트란 분명한 역할을 가지고 있으며 독립적으로 존재할 수 있는 하드웨어 또는 소프트웨어 조각을 말한다.
- 같은 기능을 가진 다른 컴포넌트로 대체할 수 있다.
- 대부분의 컴포넌트는 재사용 가능하도록 설계된다.
- 사용자인터페이스, 뱅킹 업무, 창고 관리 등 특정 목적을 가진 컴포넌트도 있다.
2. 모듈
모듈이란 프로그래밍 언어 수준에서 정의된 컴포넌트를 말한다.
- 자바 언어에서의 모듈은 메소드, 클래스, 패키지 등이 있다.
- C언어에서의 모듈은 파일, 함수 등이 있다.
3. 시스템
시스템이란 정의 가능한 책임과 목적들을 가지고있고, 소프트웨어나 하드웨어로 구성된 논리적 개체를 말한다. 그 중 서브시스템이란 대규모 시스템의 일부분으로 확정된 인터페이스를 가진다.
- 명세를 가지며 컴포넌트의 집합에 의해 구현될 수 있다.
- 컴포넌트가 변하거나 다른 컴포넌트로 대치되더라도 지속적으로 존재한다.
시스템은 다음과 같이 구성된다.

🌱 설계 방법
1. 하향식 설계
먼저 시스템의 최상위 부분을 설계한 후 하위 수준의 자세한 결정을 내리면서 점차적으로 하향한다. 최종적으로 도달하는 자세한 결정은 특정 데이터 아이템의 포맷, 사용할 개별 알고리즘 등이 된다.
2. 상향식 설계
재사용 가능한 하위 수준의 유틸리티들에 대한 결정을 내리며, 높은 수준의 구조를 만들기 위해 이것들을 어떻게 함께 배치할 것인가를 결정한다.
3. 혼용 방법
하향식 방법은 항상 시스템에 좋은 구조를 가져올 수 있고, 상향식 방법은 재사용 가능한 컴포넌트를 만들게 된다는 측면에서 유용하다는 장점을 이용하여 상향식과 하향식을 혼용한 방법이다.
🌱 설계의 종류
1. 아키텍쳐 설계 : 소프트웨어 시스템을 서브시스템과 컴포넌트로 분할
어떻게 연결되어야 하는가, 어떻게 상호작용 할 것인가, 인터페이스는?
2. 클래스 설계 : 클래스의 기능, 연관관계, 상호작용, 상태 등을 설계
3. 사용자 인터페이스 설계
4. 알고리즘 설계 : 계산 방식의 설계
5. 프로토콜 설계 : 통신 매커니즘/프로토콜의 설계
📁 설계 원리
좋은 설계의 목표
- 비용 절감으로 인한 이익 증가
- 요구사항에 부합하는지 확증
- 개발의 가속화
- 사용성(usability), 효율성(efficiency), 신뢰성(reliability), 유지보수성(maintainability), 재사용성(reusability) 등 소프트웨어 품질의 향상
🌙 원리1. 분할 정복
한번에 큰 것을 개발하는 것 보다는 작은것을 연속적으로 다루는것이 더 쉽다.
사람들을 나누어 각 부분을 작업할 수 있다. 자동차 설계를 엔진 설계, 몸체 설계 등으로 나눌 수 있다.
소프트웨어 시스템을 작은 부분으로 나누었을때의 이득은 다음과 같다.
- 개발 작업의 병행 진행으로 인한 개발 기간을 단축
- 개별 소프트웨어 엔지니어는 자신의 분야에서 전문성을 높일 수 있다.
- 각 컴포넌트는 더 작아지고 더 이해하기 쉬워진다.
- 다른 부분을 변경하거나 교체할 필요 없이 부품을 교체하거나 변경할 수 있다.
소프트웨어는 다음과 같이 분리된다.
- 분산 시스템 : 클라이언트와 서버로 분리될 수 있다.
- 시스템 : 여러개의 서브시스템으로 분리될 수 있다.
- 서브시스템 : 하나 이상의 패키지로 분리될 수 있다.
- 패키지 : 여러개의 클래스로 분리될 수 있다.
- 클래스 : 여러개의 메소드로 분리될 수 있다.
🌙 원리2. 응집력 향상
서브시스템이나 모듈이 서로 관련 있는 것들은 같이 두고 그 외의 것들을 배제할 경우 높은 응집력을 가진다.
전체 시스템을 이해하거나 변경하기 쉬워진다.
응집도의 유형에는 응집력이 높은 순으로 기능적 응집도, 계층적 응집도, 순차적 응집도, 교환적 응집도, 절차적 응집도, 시간적 응집도, 실용적 응집도가 있다.
1. 기능적 응집도
특정 결과를 계산하기 위한 코드만이 모여있고 나머지는 배제할 때 달성된다.
모듈이 단일 작업을 수행하고 하나의 결과만을 낼 때 달성된다.
기능적 응집의 사례에는 수학 함수 계산 모듈(sine, cosine 등), 대출금에 대한 이자 계산 모듈, 화학 공적에 필요한 이론적 최대 비율을 계산하는 화학 공정 제어 모듈 등이 있다.
기능적 응집도를 가진 모듈은 다음과 같은 장점을 갖는다.
이해하기 쉽다 : 단일 기능, 외부에 영향 미치지 않음
재사용하기 쉽다 : 정해진 기능 이외의 side-effect가 없기 때문
대체하기 쉽다 : 그래서 유지보수가 수월해진다.
2. 계층적 응집도
연관되는 서비스를 제공하거나 접근하는 기능들을 같은 수준의 계층에 모아놓고 그 이외의 것은 배제한다.
각 층은 계층을 형성하고, 상위 층은 하위 층의 서비스에 접근하며 하위층은 상위층에 접근할 수 없다.
계층이 프로시저의 집합을 통해 서비스를 제공할 때, 프로시저의 집합을 API(Application Programming Interface)라고 한다.
계층적 응집은 다른 층에 영향을 주지 않고 API만 복제하여 층을 대체할 수 있다는 장점이 있다.
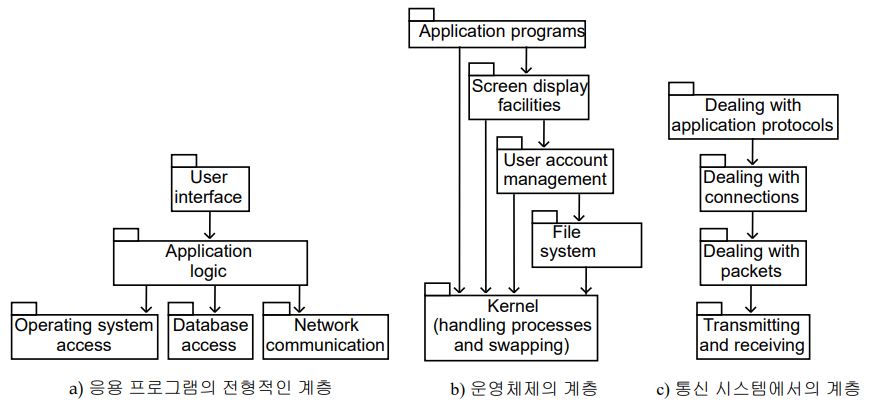
단일 계층 형성 서비스에는 다음과 같은 종류가 있다.
- 연산을 위한 서비스 - 데이터 전송 서비스 - 데이터 저장 서비스 - 보안 관리 서비스 - 사용자 상호작용 서비스 - 운영체제 접근 서비스 - 하드웨어 상호작용 서비스
3. 순차적 응집도
한 프로시저의 출력이 다음 프로시저의 입력이 될 때 이들을 함께 두고 나머지는 배제한다.
예를 들어 문서 인식 서브 시스템을 보자.
첫번째 모듈은 비트맵을 입력으로 받아 글자를 구성하는 구획으로 나눈다.
두번째 모듈은 첫번째 모듈의 결과를 입력으로 받아, 모양을 인식하고 확률을 결정한다.
세번째 모듈은 확률을 사용하여 단어를 결정한다.
4. 교환적 응집도
특정 데이터에 접근하거나 조작하는 요소는 같이 두고, 그 이외의 것은 배제한다.
객체지향 개념의 가장 큰 장점 중 하나가 교환적 응집을 보장하는 것이다.
좋은 교환적 응집도를 갖는 클래스는 특정 자료를 저장하고 조작하는 시스템의 기능을 한 클래스 안에 포함시키는 경우 혹은 클래스가 그 데이터를 조작하는 것 외의 일은 하지 않는 경우를 만족한다.
교환적 응집도의 장점은 데이터에 대한 변경을 수행할 필요가 있을 때, 한곳에서 관련된 모든 코드를 찾을 수 있다.
5. 절차적 응집도
차례로 수행되는 프로시저를 모아놓는 경우를 말한다.
한 프로시저의 결과가 다음 프로시저의 입력으로 제공될 필요가 없어 순차적 응집도보다 약하다.
순차적 응집도는 데이터 및 제어에 의해 묶이고, 절차적 응집도는 제어에 의해 묶이는 차이점이 있다.
예를 들어 첫번째 프로시저는 데이터베이스에서 부품 번호 읽기를 수행하고, 두번째 프로시저는 유지보수 파일에 수리 기록 갱신을 수행하는 경우가 있다.
첫번째 프로시저의 결과가 두번째 프로시저의 입력으로 사용되지 않지만, 순서대로 수행되는 프로시저이므로 두 프로시저의 모음은 절차적 응집도를 만족한다.
6. 시간적 응집도
프로그램의 수행에서 같은 시점에 수행될 연산들을 같이 두고 나머지는 배제.
절차적 응집도보다 약하다.
예를 들어 시스템의 시작이나 초기화 기간동안 사용되는 코드들을 같이 모아둔 것이 있다.
7. 실용적 응집도
논리적으로 다른 응집 단위에 배치될 수 없는 관련 유틸리티들을 함께 두는 경우.
이때 유틸리티란 다른 많은 서브시스템에 널리 활용되며 재사용을 위해 설계된 프로시저나 클래스를 말한다.
예를 들어 java.lang.Math 클래스가 있다.
🌙 원리3. 결합력을 낮춘다.
결합은 두 모듈 사이에 의존관계가 있을 때 발생한다.
의존관계가 존재하면 한 부분이 변경되면 다른 부분의 변경을 유발한다.
의존관계가 복잡하변 컴포넌트들이 어떻게 수행되는지 한 눈에 보기 어렵다.
결합도의 유형에는 내용 결합도, 공통 결합도, 제어 결합도, 스탬프 결합도, 자료 결합도, 루틴 호출 결합도, 타입 사용 결합도, 포함 결합도, 외부 결합도가 있다.
1. 내용 결합
한 컴포넌트가 다른 컴포넌트의 내부 데이터를 비밀리에 수정하는 경우를 말한다.
내용 결합을 피하기 위해 모든 인스턴스 변수를 캡슐화(encapsulation)해야한다.
예를 들어 private으로 선언하거나, getter와 setter함수를 제공한다.
내용결합의 나쁜 형태 중 하나는 인스턴스 변수 안에 포함된 인스턴스 변수를 직접적으로 수정하는 경우가 있다.
public class Line {
private Point start, end;
...
public Point getStart() { return start; }
public Point getEnd() { return end; }
}
public class Arch {
private Line baseline;
...
void slant(int newY) {
Point theEnd = baseline.getEnd();
theEnd.setLocation(theEnd.getX(),newY);
}
}
Line은 setter가 없기때문에 Line의 인스턴스 baseline은 변경할 수 없다.
그러나 Point 타입의 setLocation()을 사용하면 Line이 은밀하게 변경된다. 이렇게 변경되는 경우가 내용 결합이 된 경우이다.
2. 공통 결합
전역 변수를 사용할 때 항상 발생한다.
전역변수를 사용하는 모든 모듈은 전역변수를 선언한 모듈과 결합된다.
공통 결합의 약한 형태는 어떤 변수가 시스템의 클래스 일부에 의해 접근 가능할 때, 예를들어 Java 패키지가 있다.
??
시스템 전체가 사용하는 디폴트 값을 나타내는 전역 변수는 허용할만하다.
시스템 전체가 사용하는 대부분의 변수는 실제로 변수가 아니라 상수이다. 예를들면 java.lang.Math 패키지의 상수 PI 등이 있다.
싱글톤(singleton) 패턴은 객체에 캡슐화된 전역 변수를 제공한다.
3. 제어 결합
프로시저가 플래그나 커맨드를 사용해서 다른 프로시저를 호출하여 제어하려는 경우에 발생한다.
플래그나 커맨드는 다른 프로시저가 하는 일을 제어하기 위한 것을 말한다.
변경하려면 호출하는 메소드와 호출되는 메소드 모두를 변경해야한다.
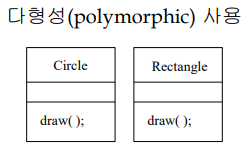
오퍼레이션의 다형성(polymorphic)을 사용하면 제어 결합을 피할 수 있다.
제어 결합을 감소시키기 위한 방법 중 하나는 look-up 테이블을 만드는 것이다.
look-up 테이블이란 명령이 내려질 때 호출돼야하는 메소드로 매핑하는 것.
중첩된 if-else문보다는 구조면에서 더 간단하다.
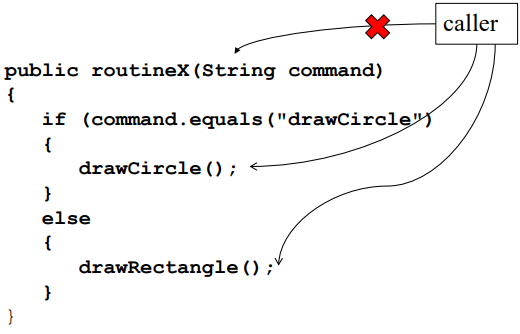
예를 들어 위와 같은 경우, routineX는 제어결합을 갖는 메서드의 사례이다. caller에서 command가 바뀌면 routineX의 내부도 바뀌어야한다.
이때 caller가 routineX를 직접 호출하는 것이 아니라, drawCircle이나 drawRectangle을 직접 호출하면 제어결합을 피할수 있다.
혹은 다형성을 이용하여 제어결합을 피할 수 있다. 만약 오른쪽과 같이 circle, rectangle 클래스가 있고, 이 두 클래스의 수퍼클래스인 Shape 클래스와 그 내부에 draw() 메서드가 있다고 할 때, Shape 클래스를 이용해서 파라미터를 전달하면 다형성이 이용되어 제어결합을 피할 수 있다.
4. 스탬프 결합
응용클래스들 중 하나가 메소드 매개변수의 타입으로 선언되는 경우를 말한다.
다른 클래스를 매개변수로 사용하기 때문에 시스템의 변경이 쉽지 않다. 한 클래스를 재사용하려면 다른 클래스도 자동으로 재사용되어야한다.
스탬프 결합을 줄이기 위해서는 인터페이스를 매개변수로 사용하거나, 단순 변수를 전달하는 방법을 사용할 수 있따.
public class Emailer
{
public void sendEmail(Employee e, String text)
{...}
...
}
예를 들어 위와 같은 코드가 있다. sendEmail이 매개변수로 Employee라는 응용클래스 타입을 사용하므로 스탬프 결합이 존재한다. 이를 아래 코드와 같이 단순변수를 사용하여 개선할 수 있다.
public class Emailer
{
public void sendEmail(String name, String email, String text)
{...}
...
}
혹은 인터페이스를 이용하여 개선할 수도 있다.
public interface Addressee
{
public abstract String getName();
public abstract String getEmail();
}
public class Employee implements Addressee {…}
public class Emailer
{
public void sendEmail(Addressee e, String text)
{...}
...
}
5. 자료 결합
메소드의 매개변수 타입이 기본 자료형이거나 단순한 라이브러리 클래스인 경우를 말한다.
메소드의 매개변수가 많으면 많을수록 결합도가 높아진다. 그 메소드를 사용하는 모든 메소드들이 모든 매개변수를 전달해주어야하기 때문이다.
불필요한 매개변수를 줄임으로써 결합도를 낮출 수 있다.
자료 결합과 스탬프 결합 간데 trade-off 관계가 존재한다.
• 자료 결합: 3 ~ 4 매개변수 • 스탬프 결합: > 4 매개변수
6. 루틴 호출 결합
하나의 루틴(객체지향에서는 메소드)이 다른 루틴을 호출할 때 발생하는 결합을 말한다.
루틴들은 서로의 행위에 의존하기 때문에 결합이 있다.
루틴 호출 결합은 어느 시스템이나 항상 존재한다.
어떤 계산을 위해 두 개 이상의 메소드를 반복해서 사용하는 경우, 이런 부분을 캡슐화하여 하나의 루틴으로 정의하여 루틴 호출 결합을 줄일 수 있다.
예를 들어 그래픽에서 다음 순서대로 사용하는 코드를 여러 번 작성해야 할 경우가 있다.
aShape.drawBackground();
aShape.drawForeground();
aShape.drawBorder();
7. 타입 사용 결합
어떤 모듈이 다른 모듈에서 정의한 자료형을 사용할 때 발생한다.
클래스 안에서 인스턴스 변수나 지역 변수를 선언할 때 다른 클래스의 타입으로 선언하는 경우에는 언제든지 발생한다.
만일 타입의 정의가 바뀐다면 타입을 사용하는 쪽도 영향을 받는다.
항상 변수의 타입을 선언할 때는 요구되는 오퍼레이션을 포함하는 가장 일반적인 클래스나 인터페이스를 사용한다.
8. 포함 결합
Java의 경우 컴포넌트가 패키지를 import할때, C나 C++의 경우 컴포넌트가 다른 파일을 include하는 경우를 말한다.
imported 컴포넌트는 importing 컴포넌트에 노출된다.
imported 컴포넌트에 변경이 가해질 때 importing 컴포넌트 안의 어떤 요소와 상충될 경우, importing 컴포넌트의 변경이 필요하다.
예를 들어 imported 컴포넌트 안의 어떤 요소가 사용자에 의해 정의된 importing 컴포넌트의 어떤 것과 이름이 같은 경우
9. 외부 결합
어떤 모듈이 운영체제, 공유 라이브러리, 하드웨어 등에 의존하는 경우.
이 경우에는 코드에서 의존성 갖는 부분을 줄이는 것이 최선의 방법이다. facade 설계 패턴으로 외부결합을 줄일 수 있다.
🌙 원리4. 높은 수준의 추상화
상세하고 구체적인 부분을 숨기거나 상세화를 지연함으로써 복잡도를 줄여야한다.
좋은 추상화는 정보 은닉(information hiding)을 제공하고, 추상화는 불필요하게 상세한 사항을 알지 않아도 서브시스템의 근본을 알 수 있게 해준다.
클래스는 프로시저 추상화를 포함한 자료 추상화
모든 변수를 private으로 선언하면 추상성은 높아진다.
클래스 안에 메소드가 적을수록 추상화가 좋아진다.
슈퍼클래스와 인터페이스를 사용할수록 추상성이 높아진다.
메소드는 절차적 추상화이다. 보다 적은 수의 매개변수를 가진 메소드를 제공함으로써 더 나은 추상화를 달성한다.
🌙 원리5. 재사용성 증진
다른 상황에서도 다시 사용될 수 있도록 시스템의 다양한 측면을 설계한다.
재사용성 증진을 위한 주요 전략은 다음과 같다.
설계를 가능한 많이 일반화(generalization)한다.
높은 응집도, 낮은 결합도, 높은 수준의 추상화의 설계 원리를 따른다.
후크(hook)를 가진 시스템으로 설계한다.
설계를 가능한 단순화한다.
이때 hook란 다른 설계자가 기능을 추가할 수 있도록 의도적으로 추가한 설계의 일부분을 말한다.
🌙 원리6. 설계와 코드의 재사용
재사용을 통한 설계와 재사용을 위한 설계는 서로 보완적이다.
적극적으로 설계나 코드를 재사용하는 것은 다른 사람들이 투자한 재사용 컴포넌트의 이점을 얻는것이다.
코드 복사와 같은 복제(cloning)은 재사용의 형식으로 볼 수 없다.
🌙 원리7. 유연성 고려
미래에 이루어질 변경을 미리 적극적으로 예상하고 이를 준비해야한다.
변경의 종류에는 효율성 개선 목적의 코드 수정이나 기능적 요구사항의 변경 등이 있다.
유연성을 증진하는 방법은 다음과 같다
결합력을 줄이고 응집력을 높인다.
인터페이스나 수퍼클래스를 생성하여 추상화한다.
상수 사용의 경우 하드코딩을 하지 않는다.
나중에 시스템을 변경해야하는 사람의 선택권을 제한하지 말아야하므로, 선택의 여지를 남겨야한다.
hook 추가와 같은 기법으로 유연하게 설계하여, 재사용 가능한 코드를 사용하고 코드를 재사용 가능하게 만들어야한다.
🌙 원리8. 노후화 예측
기술 또는 환경의 변화에도 소프트웨어를 계속 운영하거나 쉽게 변경할 수 있도록 계획한다.
기술의 초기 배포판의 사용을 피해야한다.
특정 환경에서만 사용되는 라이브러리의 사용은 피해야한다.
문서화되지 않은 기능이나 거의 사용되지 않는 기능의 사용은 피해야한다.
장기간 지원을 제공할 가능성이 낮은 회사가 제공하는 소프트웨어나 하드웨어의 사용은 피해야한다.
표준 언어나 다수의 회사에 의해 지원되는 기술을 사용해야한다.
🌙 원리9. 이식성 고려
가능하면 많은 플랫폼에서 실행할 수 있도록 소프트웨어를 설계해야한다.
특정 환경만을 위한 기능의 사용은 피해야한다.
예를 들어서 MS-Windows에서만 가용한 라이브러리 사용을 피한다.
🌙 원리10. 테스트 가능성 고려
테스트가 쉽도록 설계해야한다.
소프트웨어가 자동으로 테스트할 수 있도록 프로그램을 설계한다.
코드의 모든 기능이 GUI를 통하지 않고도 외부 프로그램에 의해 구동될 수 있도록 설계한다.
Java 언어에서는 각각의 클래스에 main() 함수를 만들어 다른 메소드들을 검사할 수 있게 한다.
🌙 원리11. 방어적인 설계
컴포넌트를 다른 사람이 항상 설계 의도에 맞게 사용할 것이라고 생각하지 않는다.
컴포넌트를 부적절하게 사용할 모든 경우를 대비해야한다.
컴포넌트에 대한 모든 입력이 유효한지 체크해야한다. precondition
하지만 과도한 방어 설계는 불필요한 반복적 체크를 유발한다.
효율적이고 체계적인 방법으로 방어적 설계를 할 수 있는 기술로 계약에 의한 설계가 있다.
각 메소드가 호출자와 명시적으로 계약을 맺는 방법이다.
계약에는 다음과 같은 assertion이 존재한다.
- 호출된 메소드가 실행될 때 true여야 할 전제조건(preconditions)
- 호출된 메소드가 실행을 완료할 때 true인지 확인하기 위한 후행조건(postconditions)
- 호출된 메소드가 실행되는 동안 변경되지 않아야 할 불변조건(invariants)
📁 아키텍처 패턴
건축에서 분명한 양식이나 유형이 있듯이 소프트웨어 구조에도 유형이 존재한다.
컴포넌트를 이용하여 융통성 있는 시스템을 설계할 수 있다.
1. 계층구조 스타일
계층구조는 각 서브시스템이 하나의 계층이 되어 하위층이 제공하는 서비스를 사용한다. 상위층에서는 하위층을 서비스의 집합으로만 여긴다.
하나의 계층은 바로 아래 계층과만 미리 정의된 API를 이용하여 커뮤니케이션한다.
복잡한 시스템은 추상 수준을 높이면서 층을 포개어 구성하 ㄹ수 있다.
UI를 위한 별도의 층을 갖는것이 중요하고, UI의 바로 아래층은 유스케이스에서 결정된 어플리케이션 기능들을 제공하도록 설계한다.
하위층은 공통적/일반적인 서비스를 제공한다. 예를들어 Network Communication이나 Databas Access 등이 있다.
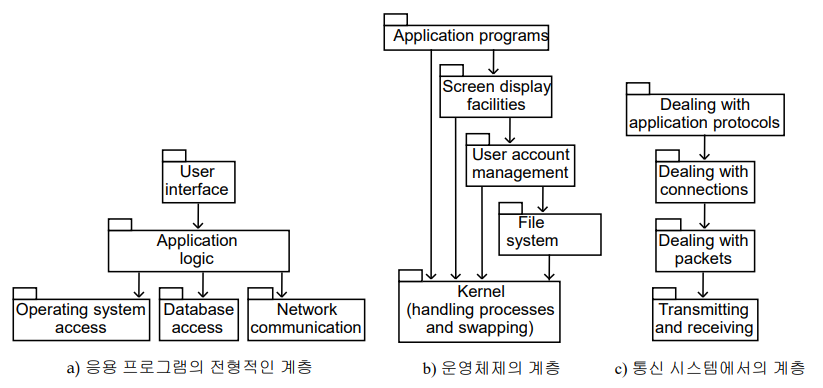
계층 구조의 설계 원리는 다음과 같다.
1. 분할 정복 : 분리된 계층은 독립적으로 설계될 수 있다.
2. 응집도 향상 : 계층 응집도(층 내부에 관련 서비스가 응집된다)
3. 결합력 감소 : 잘 설계된 하위층은 상위층에 대해 알지 못하고, 층 사이의 연결은 API를 통해 이루어진다.
4. 추상화 증진 : 하위층이 어떻게 구현되었는지 상세히 알 필요가 없다.
5. 재사용성 증진 : 하위층은 범용적으로 설계될 수 있다.
6. 재사용 확대 : 다른 곳에서 개발된 층을 재사용할 수 있다.
7. 융통성 : 하위층을 기반으로 새 기능을 추가하거나 상위층을 교체할 수 있다.
8. 노후화 예측 : 컴포넌트를 분리된 층에 고립시킴으로써 노후화에 대비할 수 있다(?)
9. 이식성 : 모든 종속적인 기능을 하나의 계층으로 격리시킬 수 있다.
10. 테스트 가능성 : 각 층은 독립적으로 테스트할 수 있다.
11. 방어적 설계 : 각 층의 API를 통해 엄격한 assertion 체크를 수행할 수 있다.
2. 클라이언트-서버 스타일
서버란 연결을 기다리고 처리해주는 역할을 수행하고, 클라이언트란 서비스를 제공받으려고 연결을 시도하는 하나 이상의 컴포넌트를 말한다.
Peer-to-Peer 스타일이란 클라이언트-서버 스타일의 확장된 형태로, 여러 호스트에 분산되어있는 여러 소프트웨어 컴포넌트로 구성된다.
예를 들어 메신저를 위한 P2P 아키텍처를 보자.
두 피어 노드가 통신하여 서로의 존재를 파악하거나, 위치를 찾기위해 서버를 이용할 수도 있다.
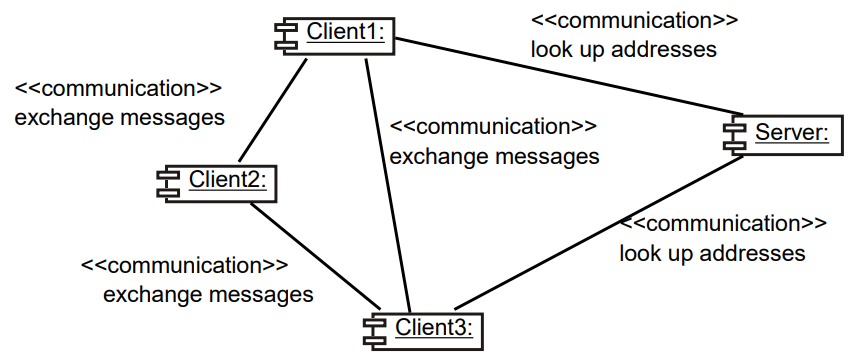
클라이언트-서버 스타일의 설계 원리는 다음과 같다.
1. 분할 정복 : 클라이언트와 서버로 확실히 분리되어 별도로 개발할 수 있다.
2. 응집도 향상 : 서버는 클라이언트에게 응집도 높은 서비스를 제공한다.
3. 결합력 감소 : 단순 메세지를 교환하는 하나의 통신 채널이 존재한다.
4. 추상화 증진 : 분리된 분산 컴포넌트는 좋은 추상화를 나타낸다.
5. 재사용성 증진 : X
6. 재사용 확대 : 분산 시스템을 구축하기 위한 좋은 프레임워크는 발견할 수 있으나 클라이언트-서버 시스템이 가장 구체적이다.
7. 융통성 : 서버와 클라이언트를 추가하여 쉽게 분산 시스템을 재구성할 수 있다.
8. 노후화예측 : X
9. 이식성 : 서버를 이식하지 않고 새로운 플랫폼을 위한 클라이언트를 작성할 수 있다.
10. 테스트 가능성 : 서버와 클라이언트를 별도로 테스트할 수 있다.
11. 방어적 설계 : 메세지 처리 코드에서 엄격한 체크를 수행할 수 있다.
3. 브로커 스타일
여러 다른 노드에 소프트웨어 시스템을 투명하게 분산시킬 수 있다.
객체가 어디에 위치하는지 알 필요 없이 원격 객체의 메소드를 호출할 수 있다.
CORBA(Common Object Request Broker Architecture)는 잘 알려진 개방형 표준을 말한다.

4. 트랜잭션 처리 스타일
연속적인 입력을 하나씩 읽어 트랜잭션으로 명시한다.
이때 트랜잭션이란 시스템에 저장된 데이터에 변경을 가하는 명령들의 집합을 말한다.
각 트랜잭션에 대해 무엇을 할 것인지 결정한 다음, 그 트랜잭션을 처리할 수 있는 컴포넌트에 배정한다.
이때 트랜잭션 dispatcher란 트랜잭션을 컴포넌트에 배정하는 역할을 수행하는 컴포넌트를 말한다.
예를 들어 항공권 예약 시스템의 트랜잭션 처리는 아래와 같다.
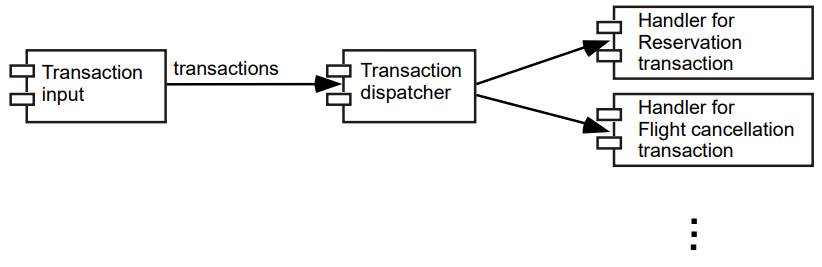
5. 파이프 필터(Pipe & Filter) 스타일
비교적 단순한 형태의 데이터 스트림이 프로세스에 차례로 전달되어 처리되는 구조를 말한다.
데이터는 파이프라인으로 계속 주입된다.
입력 데이터를 가공 또는 특정한 형태로 변환시키는 filter가 존재한다.
프로세스(filter)는 병렬적으로 실행할 수 있다.
아키텍쳐는 매우 융통적이다. 거의 모든 컴포넌트가 삭제될 수 있고, 대체될 수 있고, 추가될 수 있으며, 어떤 컴포넌트들은 순서가 재배치될 수도 있다.
예를 들어 Java의 입출력 시스템은 아래와 같다.
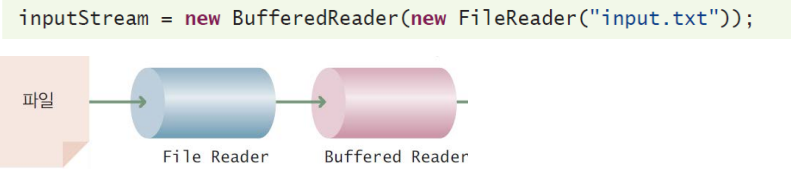
파이프 필터 스타일의 예시는 아래와 같다.
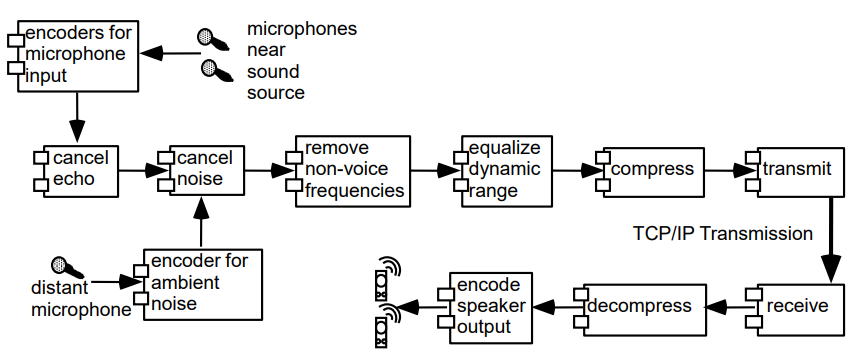
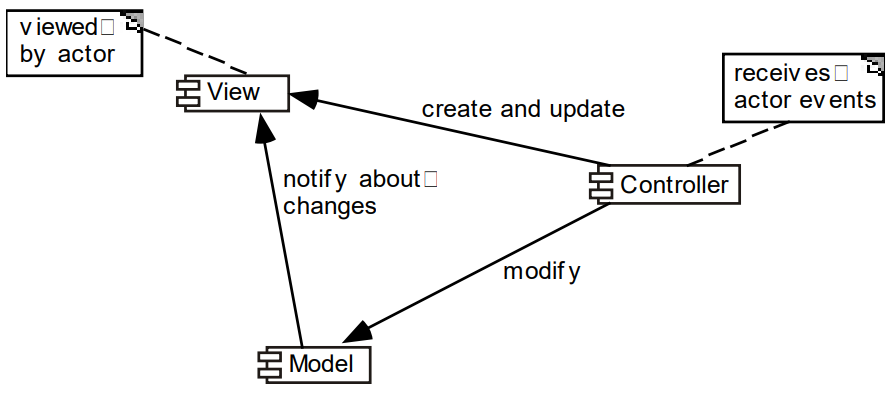
6. MVC 스타일
사용자 인터페이스 계층을 시스템의 다른 부분과 분리하기 위한 스타일을 말한다.
- 모델(Model) : 내용에 해당하는 부분으로, 사용자에게 보여지고 조작될 수 있는 클래스의 인스턴스를 포함한다.
- 뷰(View) : 모델에 있는 데이터를 사용자 인터페이스에 보여지도록 표현해주는 역할을 담당한다.
- 제어(Controller) : 사용자가 모델 또는 뷰와 상호작용하는 것을 제어하는 역할을 수행한다.
📁 좋은 설계 결정을 내리는 기술
우선순위와 목표를 사용하여 대안 중에서 결정한다.
목표 : 달성하고자 하는 계량적인 값
우선순위 : 품질 특성이 상충될 때 절충할 방법을 제시한다.
우선순위와 목표의 예시는 다음과 같은 경우가 있다.
보안 : 알려진 암호 해독 기법을 사용하여 400MHz 프로세서로 100시간 안에 암호를 풀지 못해야한다.
유지보수성 : 구체적 목표 없음
CPU 효율성 : 400MHz 프로세서에서 수행될 때 1초 이내에 사용자에게 응답해야한다.
네트워크 대역 효율성 : 트랜잭션 당 8KB 이상의 데이터 전송을 요구하지 않아야한다.
메모리 효율성 : 20MB 램 이상 소요되면 안됨
이식성 : 리눅스 뿐만 아니라 윈도우7, 10에서도 실행되어야한다.
설계안을 결정하는 순서는 다음과 같다.
- 1단계 : 설계 결정을 위해 설계 대안을 모두 나열하고 기술한다.
- 2단계 : 목표와 우선순위 관점에서 각 설계 대안에 대한 장점과 단점을 기술한다.
- 3단계 : 하나 이상의 목표를 만족시키지 못하는 설계 대안은 배제한다.
- 4단계 : 목표를 가장 잘 만족시키는 설계 대안을 선택한다.
- 5단계 : 계속되는 설계 의사결정을 위해 우선순위를 조정한다.
설계 대안을 평가한 사례로 아래와 같은 경우가 있다.
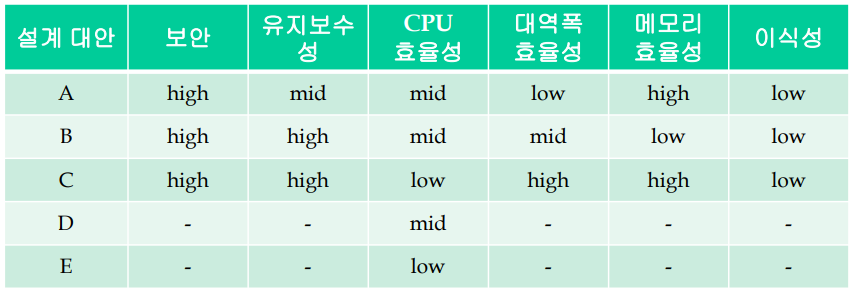
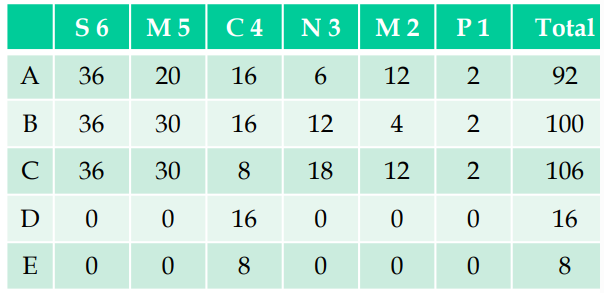
보안 6점, 유지보수성 5점, CPU 효율성 4점, 대역폭 효율성 3점, 메모리 효율성 2점, 이식성 1점으로 우선순위 값을 부여한다.
high는 6점, mid는 4점, low는 2점으로 평가 값을 부여한다.
최종 계산 결과 C안이 선택된다.
📁 소프트웨어 아키텍쳐
소프트웨어 시스템에 대한 전반적인 구조를 설계하는 과정을 말하며, 다음과 같은 사항들을 포함한다.
소프트웨어 아키텍쳐에서는 소프트웨어 시스템을 서브시스템으로 분할하고, 이들이 어떻게 상호작용하는지를 결정한다.
또한 인터페이스를 결정한다. 아키텍쳐는 설계의 핵심이기 때문에 소프트웨어 엔지니어 모두가 이해하고 있어야하며, 아키텍쳐는 시스템의 전체적인 효율성, 재사용성, 유지보수성을 제한한다.
소프트웨어 아키텍쳐 모델을 개발하는 이유는 다음과 같다.
- 소프트웨어 시스템을 누구나 잘 이해할 수 있게 한다.
- 시스템의 일부를 독립적으로 작업할 수 있게 한다.
- 시스템의 확장을 준비하기 위함이다.
- 재사용과 재사용성을 용이하게 한다.
소프트웨어 시스템의 아키텍쳐가 표현되는 여러 관점(view)은 다음과 같다.
- 논리적으로 분할된 서브시스템
- 서브시스템 사이의 인터페이스
- 실행 시점에서의 컴포넌트 사이의 동적인 인터액션
- 서브시스템 사이에 공유되는 데이터
- 런타임에 존재하는 컴포넌트들과 그들이 위치하게 될 machine이나 장치
아키텍처 모델 개발 과정은 다음과 같다.
1) 아키텍처 아웃라인 작성
주요 요구사항 및 유스케이스를 기반으로 작성한다.
먼저 데이터베이스, 하드웨어 장치, 주요 소프트웨어 서브시스템 등 필요한 주 컴포넌트를 결정한다.
다음으로 다양한 아키텍처 패턴 중에서 적절한 아키텍처 패턴을 선택한다.
2) 아키텍처 정제 및 개선
컴포넌트가 상호작용하며 서로 인터페이스하는 주 경로를 찾는다.
데이터와 함수를 여러 컴포넌트에 어떻게 분배할지 결정한다.
기존 프레임워크를 재사용할 수 있는지, 프레임워크를 구축할 수 있는지 결정한다.
3) 각 유스케이스를 살펴보고 그것을 실현할 수 있도록 아키텍처를 조금씩 고쳐나간다.
컴포넌트 인터페이스를 확정한다.
4) 아키텍처를 성숙시킨다.
모든 UML 다이어그램은 아키텍처 모델을 기술하는데 유용하다.
아키텍처를 정의하기 위한 UML 다이어그램 종류는 다음과 같다.
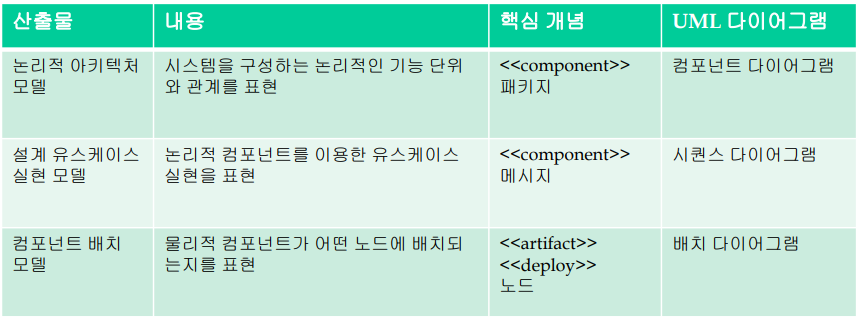
컴포넌트 다이어그램
시스템을 구성하는 논리적인 기능 단위와 관계를 표현한다.
다음 요소들로 구성된다.
- 논리적 컴포넌트 : 논리적 기능 단위
<<component>> 스테레오 타입으로 표현한다.
- 인터페이스 : 논리적 컴퓨넌트가 제공하는 기능에 대한 명세를 정의
컴포넌트와 인터페이스 간의 실선은 해당 인터페이스의 기능을 컴포넌트가 실현한다.
점선 : 인터페이스에 명세된 기능을 어느 컴포넌트가 이용하는지를 의미한다.
- 패키지
내부에 또다른 패키지나 클래스가 존재한다.
내부의 클래스의 연산이 외부의 다른 패키지나 컴포넌트로부터 직접 호출한다.
컴포넌트의 경우 인터페이스를 통해 기능을 명세한다.
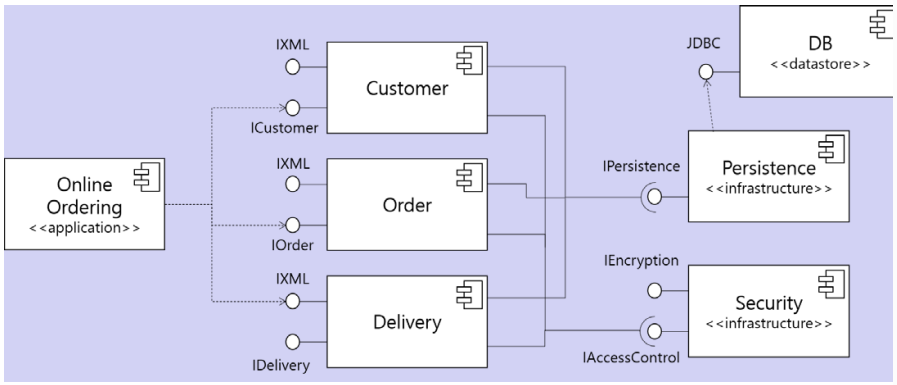
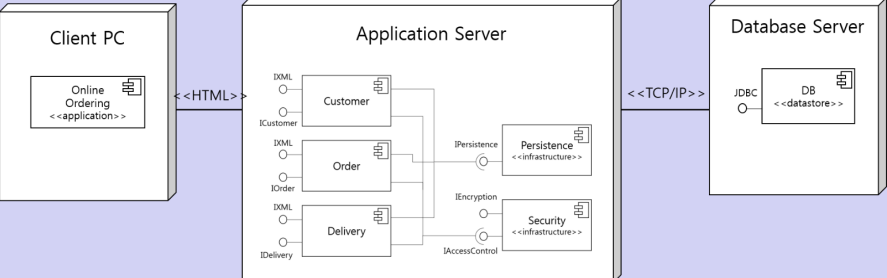
배치 다이어그램
개발될 시스템의 소프트웨어 및 하드웨어 컴포넌트의 물리적인 배치 관계를 나타낸다.
구성요소는 다음과 같다.
노드 : 물리적인 컴퓨팅 유닛
플랫폼 소프트웨어 : 응용 소프트웨어의 실행 환경
컴포넌트 : 노드에 배치되는 컴포넌트
링크 : 시스템의 통신 경로
📁 아키텍처 문서화
설계 문서는 더 좋은 설계를 만들기 위해 도움이 된다.
구현을 시작하기 전에 중요한 설계 이슈를 고려하게 한다.
참여 그룹이 설계를 검토하고 개선할 수 있게 한다.
설계 문서는 다음과 같은 참여자들 간의 커뮤니케이션 수단이다.
설계를 구현할 사람
미래에 설계를 수정할 필요가 있는 사람
설계한 시스템과 인터페이스를 갖는 새로운 시스템이나 서브시스템을 생성할 사람
문서의 내용에는 목적, 우선순위, 설계의 outline, 주요 설계 이슈, 설계에 대한 여타 상세 사항 등이 있다.
- 목적
문서가 기술하는 대상 시스템이 무엇인지 기술한다.
설계에 의해 구현될 요구사항에 대한 참조(traceability)
-우선순위
설계 과정을 안내하기 위해 사용될 우선 순위를 기술
- 설계의 outline
개괄적인 소개를 하기 위해 설계에 대한 상위 수준에서의 기술
- 주요 설계 이슈
해결해야할 중요한 설계 이슈에 대한 토의
고려해야할 가능한 대안과 최종 결정 및 그 결정에 대한 근거 등을 기술
-설계에 대한 여타 상세 사항
아직 언급되지 않은 것 중 독자가 반드시 알아야 할 여타 상세 사항
📁 클래스 설계 5대 원칙
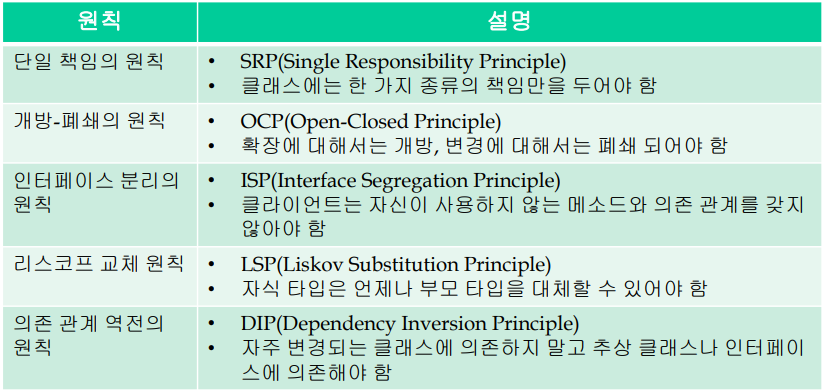
1. 단일 책임의 원칙(SRP, Single Responsibility Principle)
클래스는 한 가지 종류의 책임만을 가져야한다.
객체의 약한 결합(loose coupling)과 강한 응집력(tight cohesion)을 실현한다.
설계 수정 및 교체 등의 작업, 유지보수 작업을 용이하게 한다.
설계 시간이 다소 길어진다.

2. 개방-폐쇄의 원칙(OCP, Open-Closed Principle)
확장에 대해서는 open, 변경에 대해서는 close
모듈 자체를 변경하지 않고도 그 모듈을 둘러싼 환경을 바꿀 수 있어야한다는 뜻이다.
변하는(확장되는) 것과 변하지 않는(폐쇄되어야하는)것을 엄격하게 구분한다.
이 두 모듈이 만나는 지점에 인터페이스를 정의한다.
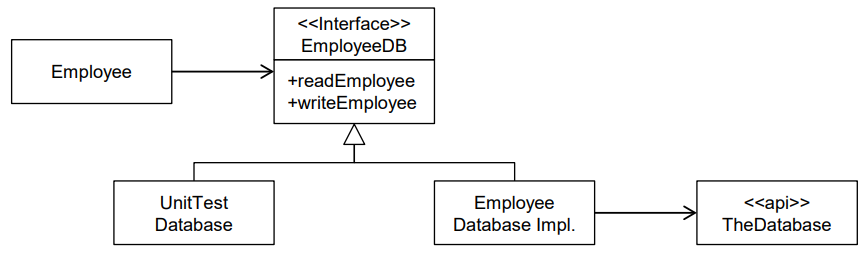
OCP를 위배한 사례는 다음과 같다.
EmployeeDB 클래스의 구현이 변경되면 Employee 클래스도 다시 빌드한다.
Employee는 EmployeeDB를 통해 데이터베이스 API에도 묶여있다.

3. 인터페이스 분리의 원칙(ISP, Interface Segregation Principle)
클라이언트는 자신이 사용하지 않는 메소드와 의존관계를 갖지 않아야한다.
여러개의 클라이언트가 어떤 클래스를 이용하는 경우, 각 클라이언트가 해당 클래스의 특정 부분만을 이용하는 경우가 있다.
예를 들어 인터페이스 분리의 원칙을 적용하기 전 다이어그램은 다음과 같다.
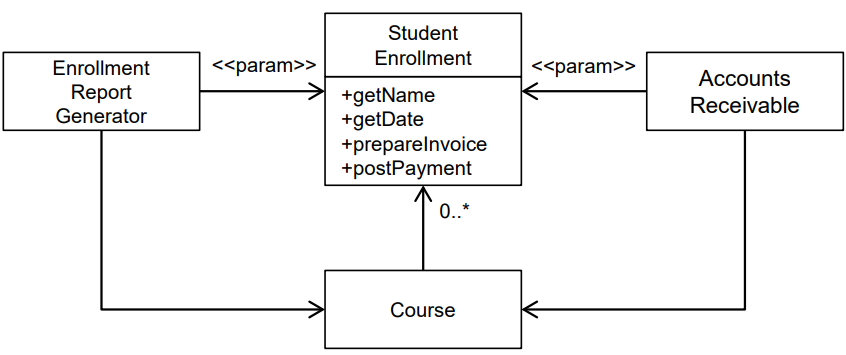
위 다이어그램에서 클라이언트에게 딱 필요한 메소드만 있는 인터페이스를 제공해보자. 필요하지 않은 메소드에서 클라이언트를 보호하며 클라이언트가 기대하는 메소드만 전달할 수 있다.
아래 예시와 같다.
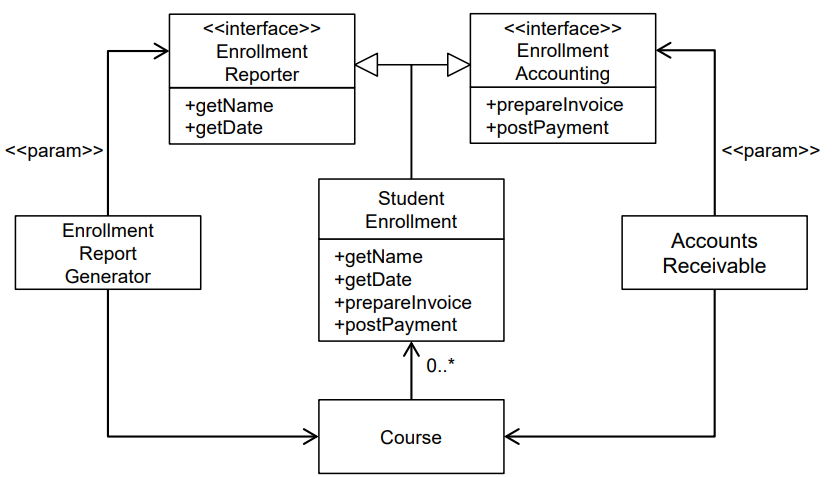
4. 리스코프 교체 원칙(LSP, Liskov Substitution Principle)
자식 타입은 언제나 부모타입을 대체할 수 있어야 한다.
올바른 상속 구조가 갖춰야 할 특성을 가이드하고, 개방-폐쇄 원칙의 기반이 된다.
부모클래스 사용자가 자식 클래스를 부모 클래스로써 사용할 때 원래 부모 클래스를 사용하는 것처럼 그대로 사용할 수 있어야 한다.
즉 instanceof나 downcast를 할 필요가 없어야한다.
5. 의존 관계 역전의 원칙(DIP, Dependency Inversion Principle)
클라이언트는 구체적(concrete) 클래스가 아닌 인터페이스나 추상 크래스에 의존해야 한다.
구체적 클래스는 변화 가능성이 많지만 추상 클래스나 인터페이스는 상대적으로 변화 가능성이 적기 때문이다.
상위 단계의 모듈은 하위 단계에 의존하지 않아야하고,
추상적인 것이 구체적인 것에 의존하지 않아야한다.
적용하는 방법은 다음과 같다.
- 클래스 상속이 필요할 경우, 기반 클래스를 추상 클래스로 만든다.
- 클래스의 참조(reference)를 가져야 할 경우 참조 대상 클래스를 추상 클래스를 만든다.
- 함수를 호출해야하 경우, 호출되는 함수를 추상함수로 만든다.
참고
https://itchallenger.tistory.com/651
자바로 알아보는 결합도(커플링)
https://www.linkedin.com/pulse/types-coupling-ahmed-adel/ Types of Coupling As our Software grows, and the communication between it's Modules gets more complex, we come to the point where "Coupling" matters, coupling occurs when there are inter-dependencie
itchallenger.tistory.com
https://mingrammer.com/translation-10-common-software-architectural-patterns-in-a-nutshell/
[번역] 10가지 소프트웨어 아키텍처 패턴 요약
10 Common Software Architectural Patterns in a nutshell을 번역한 글입니다. 대형 엔터프라이즈 규모의 시스템들은 어떻게 설계되었는지에 대해 궁금해 한 적이 있나요? 우리는 주요 소프트
mingrammer.com
https://rutgo-letsgo.tistory.com/227
응집도(Cohesion) vs 결합도(Coupling)
응집도(Cohesion) vs 결합도(Coupling) 서론 OPP에서는 응집도는 높히고 결합도는 낮춰야 한다는 말을 많이 하게 된다. 그렇다면 실제 응집도는 무엇이고 결합도는 무엇일까? 응집도(Cohesion)란? 하나의
rutgo-letsgo.tistory.com



