목차
📁 Bottom-up으로 구문 분석(Parsing)하기

Bottom-up의 파싱 결과는 우파스로, 우측 유도의 역순이다.
terminal 심벌들로부터 시작해서 시작 심벌을 유도하는 방식이며, 생성 규칙의 RHS와 매치되는지 확인하고, 매치되면 LHS로 바꿔치기를 반복하여 진행한다.
예를 들어 아래 문법을 Bottom-up 방식으로 파싱하면 다음과 같다.


📁 LL, LR
1. LL(k)
LL이란 입력을 Left-to-right, 왼쪽에서 오른쪽으로 스캔하여, Left-most를 유도하는 것?을 말한다.
k개의 심벌을 LOOKAHEAD로 사용한다.
2. LR(k)
LR이란 입력을 Left-to-right, 왼쪽에서 오른쪽으로 스캔하여, Right-most를 유도하는 것을 말한다.
마찬가지로 k개의 심벌을 LOOKAHEAD로 사용한다.
📁 Reduce
Reduce란, S => 이고 A→ 의 생성규칙이 존재할 때, 문장형태 에서 를 A로 대치하는 것을 말한다.
즉, Bottom-up 파싱에서의 파싱 결과는 시작 심벌이 나올때 까지 reduce한 결과와 같다.
예를 들어 아래 문법을 시작 심벌이 나올때까지 reduce하는 과정, 즉 Bottom-up 파싱하는 과정은 다음과 같다.

📁 Handle
Handle이란, 한 문장 형태 안에서 reduce될 부분을 지칭한다.
즉 S => A => 의 과정이 있을 때 을 문장형태 의 handle이라고 한다.
예를 들어 아래 문법의 reduce 과정에서 Handle을 살펴보자.


이때 같은 문장 형태에서 서로 다른 두 개 이상의 Handle이 존재하는 경우, 해당 문법이 모호하다고 판단한다.
예를 들어 아래 문법을 이용하여 스트링 "id + id * id"를 파싱해보자.
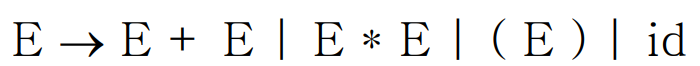

위 reduce 과정에서 두 가지 handle이 존재할 수 있으므로, 위 문법은 모호한 문법이다.
📁 Shift-Reduce Parsing
Shift란, 스택의 top에 handle이 나타날 때 까지 계속해서 입력 심벌을 스택에 옮겨 담는 작업을 말한다.
Reduce는 위에서 설명했듯이 handle을 찾으면 생성 규칙을 결정하여 LHS인 Nonterminal로 바꿔치는 작업이다.
위의 두 과정을 문법의 시작 심벌에 이를때까지 반복 수행하는 파싱이 Shift-Reduce Parsing이다.
Shift 작업의 예시를 들어보면, 다음과 같이 LOOKAHEAD 토큰 하나를 스택으로 옮길 수 있다.

이후 수행될 Reduce 작업의 예시는 다음과 같이, 생성 규칙이 X->b인 경우 스택 top에 있는 handle b를 Nonterminal 심벌 X로 바꿔치기한다.

Shift-Reduce Parsing의 예를 다음 문법을 통해 알아보자.

먼저 reduce를 진행하면 다음과 같다.

이후 스택을 사용한 Shift-Reduce 구문 분석 과정은 다음과 같다.
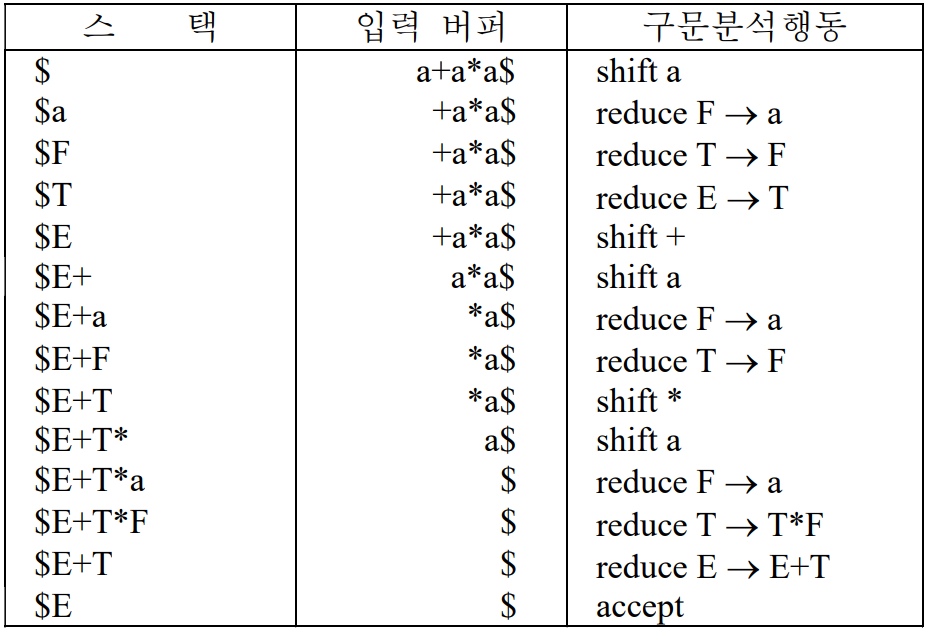
가장 초기 상태는 스택에 $를 넣고, 입력버퍼에 입력스트링과 $를 넣은 상태로 시작한다.
마지막 accept 상태는 스택 top에 시작 심벌이 있고, 입력은 모두 봐서 입력 버퍼의 입력스트링이 없어진 상태가 된다.
이때 Shift-Reduce Parsing 과정에는 여러 이슈가 존재한다.
1. 파싱의 각 과정에서, Shift와 Reduce 중 어느 작업을 수행해야 하는지를 어떻게 알 수 있을까?
예를 들어 스택에 β가 있고, 입력 글자가 b라고 가정하자.
β = αγ 이고, X -> γ 라는 생성 규칙이 존재한다면,
1) Reduce를 진행하여 스택을 αX로 만들어야하는가?
2) Shift를 진행하여 스택을 βb로 만들어야하는가?
2. β = αγ이고, 스택이 αγ이며 X -> γ 라는 생성 규칙을 따라 reduce를 진행하는 경우, 가능한 γ의 길이가 여러가지일 수 있다. 이런 경우 스택의 top 중 어디까지를 handle이라고 인식해야할까?
📁 LR Parsing Engine
위의 여러 이슈들은 '파서 상태'를 사용하여 해결할 수 있다.
스택에 입력 심벌을 shift할 때, 관련된 '파서 상태'도 함께 넣는 방식이다.
예를 들면 스택이 아래와 같이 구성될 수 있다.

'파서 상태'가 무엇인지에 따라서 reduce를 수행해야하는지, shift를 수행해야하는지가 결정되고, 얼만큼을 stack top으로 간주해야하는지 또한 결정된다.

'파서 상태'가 추가됨에 따라 파싱테이블도 <상태> X <심벌들> 의 형태가 된다.
파서는 파싱테이블을 보고 현재상태, 입력 심벌을 찾아 shift할지 reduce할지를 결정한 이후, (action table)
파서 상태를 변경시킨다. (goto table)
즉, 현재 상태가 S이고 입력문자가 a라고 가정하자.
M[S,a] = “shift S’ ” 라면 shift를 진행하여
1 .push(a)
2. push(S’)를 수행하고,
M[S,a] = “reduce X→ α ”라면 reduce를 진행하여
1. pop(2*| α |)
2. S’= top()
3. push(X)
4. push(M[S’,X])을 수행한다.
🌱 LR(0) 파싱 테이블 만들기
1. 파서 상태가 될 만한 것들이 무엇인지 정한다.
2. 각 파서 상태들 간의 상태 전이도(DFA : Deterministic Finite Automata)를 만든다.
3. 위 결과를 파싱 테이블에 담아낸다.
자세한 내용은 아래 포스팅에 작성하였다.
예를 들어 아래 문법을 이용하여 "a, a" 스트링을 파싱해보자.
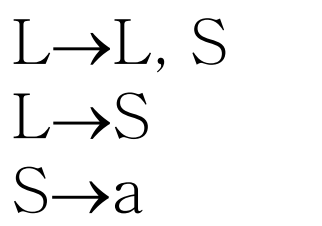
0을 시작상태라고 가정하고, 파싱 테이블은 다음과 같이 만들어진다.

파싱 과정은 다음과 같다.




