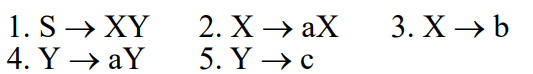목차
📁 구문 분석(Syntax Analysis)
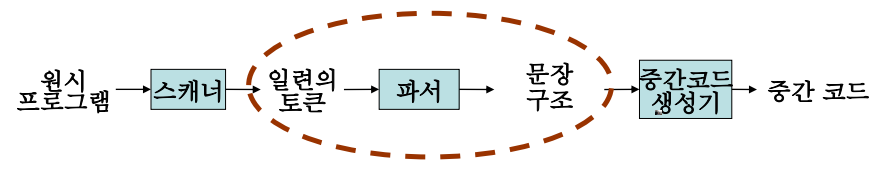
구문 분석이란 어휘 분석을 통해 토큰으로 나눈 것을 구조를 분석해서 트리모양으로 만드는 작업이다.

위 그림에서, 처음 코드를 어휘분석기(스캐너)를 통해 배열 형태의 토큰들로 만드는 것은 어휘 분석에서 하는 일이고,
어휘 분석의 결과로 얻은 토큰들의 구조를 분석해서, 이를 파스트리(Parse Tree)라는 결과물로 만드는 것이 구문 분석에서 하는 일이다.
구문 분석의 예를 들어보자.

우리말 구문, 즉 문법을 분석할 때 위와 같은 트리모양으로 분석할 수 있다.
📁
How to describe the syntax?
프로그래밍 언어 제작자가 문법을 기술(설명)하는 방법
참고로 어휘분석 때 위 질문에 대한 답은 "정규표현식"으로 기술하는 것이었다.
🌱 CFG(Context Free Grammar)
언어의 문법을 정의하는 일반적인 방법을 말한다.
간단하고 이해하기 쉬우며, 표현된 문법으로부터 자동적으로 인식기를 구현할 수 있다.
CFG 표기법에는 BNF, EBNF 등이 있다.
G = (N, T, P, S)
GFG의 문법 G는 위와 같이 표현하며,
L(G)란 문법 G로 생성되는 langauge를 뜻한다.
1. N : non terminal 심벌의 집합
non terminal 심벌이란, A, B, C와 같이 보통 알파벳 시작 부분의 대문자로 나타내는 심벌을 말한다.
대게 시작 심벌(start symbol)을 나타내는 S도 non terminal 심벌이며.
<stmt>, <expr>과 같이 <>로 묶어서 나타내기도 한다.
2. T : terminal 심벌의 집합
termianl 심벌이란, a, b, c와 같이 보통 알파벳 시작 부분의 소문자와 숫자 0~9로 나타내는 심벌을 말한다.
'+', '-'와 같은 연산자 기호와 세미콜론, 콤마, 괄호와 같은 구분자도 terminal 심벌이며,
"if", "then"과 같이 따옴표 사이에 표기된 문법의 심벌이다.
.
3. P : 생성 규칙의 집합

생성규칙이란 위 방법으로 표현된 규칙.
생성규칙 집합 P의 예시는 다음과 같다.

위 예시에서도 보이는 것처럼, A→a1 , A→a2 , …, A→ak와 같이 생성규칙의 왼쪽이 모두 A인 경우 A→a1 |a2 |…|ak 로 간단히 표기가 가능하다.
위 예시에서는 T → ‘0’| ‘1’| ‘2’ 처럼 표현 가능하다.
4. S : 시작 심벌
시작 심벌은 보통 nonterminal 심벌 S로 표현하며, 만약 아무런 언급이 없으면 첫번째 생성 규칙의 왼쪽에 있는 것이 시작 심벌이다.
🌱 정규표현식을 문법 기술에 사용하지 않는 이유
정규표현식은 어휘 분석 시에 사용되는 방법이다.
토큰을 기술하는데도 좋고, DFA로 변환하여 구현하기에도 좋다.
하지만 block, expressions, statements 등 Nested 구조의 구문을 표현하기에 적합하지 않다.
예를 들어 block의 괄호 맞추기를 보자.
📁 BNF(Backus-Naur Form)
CFG를 표기하는 방법 중 하나이다.
nonterminal 심벌은 <>로 묶어서 표기하고,
terminal 심벌은 문자스트링으로 표기한다.
<id> ::= <letter> | <id><letter> | <id><digit>
<letter> ::= a | b | c | ... | y | z
<digit> ::= 0 | 1 | 2 | ... | 8 | 9
📁 EBNF (Extended BNF)
CFG를 표기하는 방법 중 하나로, BNF 방법에 메타심벌을 도입하였다.
메타 심벌이란, 반복되는 부분이나 선택적인 부분을 간결하게 표현하기 위한 특수 심벌을 말한다.
<id> ::= <letter>{<letter>|<digit>}07
<letter> ::= a | b | c | ... | y | z
<digit> ::= 0 | 1 | 2 | ... | 8 | 9
🌱 ANTLR 문법
일종의 EBNF인 ANTLR 문법을 살펴보자.

2. How to determine if the input token stream satisfies the syntax description?
주어진 input token stream이 기술된 문법에 맞는지 어떻게 판별하는가?
참고로 어휘분석 때 위 질문에 대한 답은 "상태전이도"로 따라가며 판별하는 것이었다.
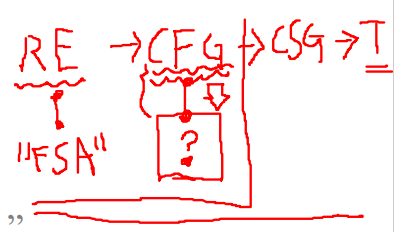
어휘 분석때는 RE로 기술한 문법을 FSA로 바꿔서, FSA를 구현하였다.
구문 분석도 마찬가지로 CFG로 기술한 문법을 "어떠한 방법"으로 바꿔서, 이 방법을 이용하여 구현할 것이다.
🌱 용어 정리
1. 문법과 언어
CFG에서 정의한 것과 같이, 문법은 생성 규칙들의 집합을 말하며 언어는 문법으로 생성되는 결과물, language를 말한다.
국어로 예시를 들어보자.

위와 같은 국어 문법이 있을 때, "똑똑한 3학년이 모였습니다" 와 같은 언어를 위 문법으로 생성할 수 있다.
"똑똑한 3학년"이 <주어구>에 해당하고, "모였습니다"가 <동사구>에 해당하며, "똑똑한 3학년"은 "똑똑한"이라는 <관형구>와 "3학년"이라는 <진 주어>에 해당된다.
2. 유도
유도란 문법에서 언어를 생성해내는 것을 말한다.
즉 위 국어문법을 보고 "똑똑한 3학년이 모였습니다"라는 언어를 생성하는 과정으로, 위 국어문법에서 "똑똑한 3학년이 모였습니다"라는 언어가 생성 가능하면 "똑똑한 3학년이 모였습니다"는 위 문법으로 유도가 가능한 언어라고 말할 수 있다.
3. 구문 분석
구문 분석이란 유도와 달리 언어에서 문법을 확인하는 것을 말한다.
구문 분석이 가능한지 확인하는 방법은, 주어진 언어가 유도되는지 확인하는 것이다.
📁 유도(derivation)
유도란 문법에서 언어(문장)을 생성하는 것을 말한다.
생성규칙을 연속적으로 적용하여 Nonterminal을 확장시키는 유도 과정을 통해 문장을 얻을 수 있다.
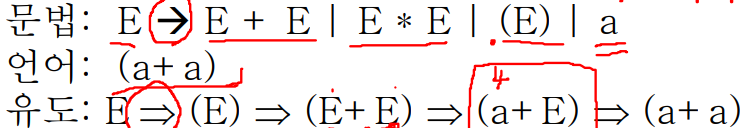
위 유도 과정 중 3, 4, 5단계를 보면 nonterminal 심벌 E를 한번에 a로 유도하지 않고 하나씩 확장하는 것 처럼, 유도 과정은 중간에 생략되는 것 없이 nonterminal 심벌 하나씩 확장해야한다.
위와 같은 유도 과정, 즉 유도 경로를 추상화시켜서 표현할 수 있는데, 이를 유도 트리라고 한다.
생성 규칙의 rhs에는 하나 이상의 nonterminal 심벌이 올 수 있으므로, 유도 과정에서 여러 nonterminal 중 어떤 심벌 먼저 확장해야하는지 결정해야한다.
- 좌측유도(leftmost derivation) : 가장 왼쪽에 있는 nonterminal부터 대치시킨다.
- 우측유도(rightmost derivation) : 가장 오른쪽에 있는 nonterminal부터 대치시킨다.
예를 들어 (a + a) * a라는 언어를 아래 문법을 이용해 유도해보자.

좌측유도와 우측유도과정은 아래와 같다.

이때 좌측 유도와 우측 유도의 유도트리는 같다.
🌱 RHS, LHS
RHS란
LHS란
📁 구문 분석, 파스(Parse)
이제 "유도"를 이용해서 구문 분석을 해보자.
구문 분석은 파스(Parse)라고도 하는데, 주어진 스트링이 정의된 문법에 의해 생성될 수 있는지의 여부(적합성)을 결정하는 과정을 말한다.
정의된 문법에 의해 스트링이 생성되는 과정이 유도이므로, 유도가 되는지 확인하면 된다.
구문 분석 결과 올바른 문장에 대해서는 '문장 구조'를, 틀린 문장에 대해서는 오류 메세지를 나타낸다.
구문분석기, 파서(Parser)는 위와 같은 구문 분석을 실행해준다.
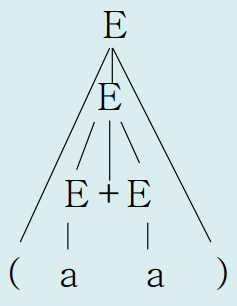
📁 파스 트리(Parse tree)
구문 분석 결과 올바른 문장은 '문장 구조'를 반환한다.
이때 '문장 구조'를 나타내기 위한 자료구조로 '파스 트리(Parse tree)'를 사용한다.
파스 트리(Parse tree)란 문장 구조를 나타내는 트리로, 문법을 나타내는 생성규칙을 적용한 유도트리와 모양이 같다.
- 루트 노드 : 정의된 문법의 시작 심벌
- 중간 노드 : 각 생성 규칙의 좌측(lhs) Nonterminal 심벌
- 단말 노드 : 주어진 스트링을 생성하는 terminal 심벌
🌱 생성규칙 번호 리스트
문법의 생성규칙을 통해 유도하는 과정에서 적용되어온 일련의 생성규칙 번호를 말한다.
유도 과정에서는 한 번에 하나의 생성규칙만 적용할 수 있으므로, 사용된 생성규칙의 번호를 하나의 리스트로 만들 수 있는 것이다.
생성규칙 번호 리스트를 통해 파스 트리를 만들 수 있는데, 문제점은 트리 -> 리스트 -> 트리의 과정은 비효율적이므로 "오버헤드"가 발생한다.
하지만 트리 전체의 자료구조가 없어도 생셩규칙 번호 리스트가 있으면 필요할때 언제든지 트리를 만들 수 있다. 즉, 리스트라는 비교적 간단한 자료구조로 트리를 저장할 수 있다는 장점이 있다.
📁 구문 분석의 두 가지 방법
1. Top-down 방식 : 루트 노드로부터 시작하여 단말노드를 생성해가며 확인하는 방식이다.
2. Bottom-up 방식 : 단말 노드로부터 루트 노드를 향하여 위로 생성하며 확인하는 방식이다.
예를 들어, 아래 문법을 이용하여 (a + a)라는 스트링을 파싱해보자.
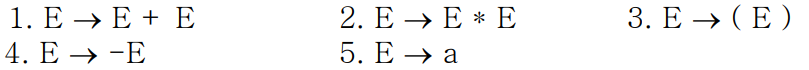
1) Top-down 방식
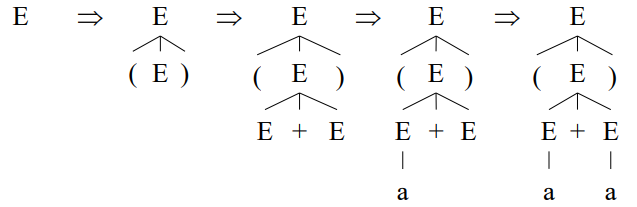
Top-down 방식은 유도를 하다가 잘못되었음을 감지하면 다시 돌아가 다른 방법을 시도해볼 수 있다. 이렇게 하면 모든 방법을 전부 시도해 볼 수 있으며, 이는 컴퓨터의 장점을 활용한 방법이라고 할 수 있다.
하지만 그러다보니 시간이 오래걸린다는 문제점이 발생한다.
2) Bottom-up 방식
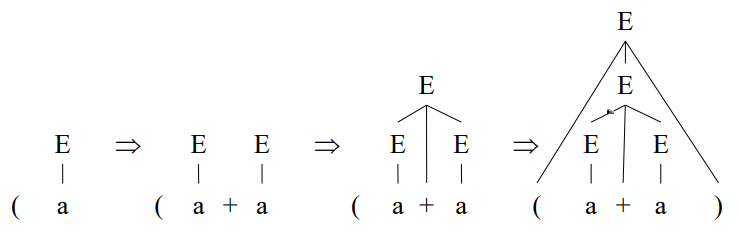
Bottom-up 방식은 토큰을 하나 받을 때 마다 트리를 연결한다.
위 과정을 보면, 가장 먼저 ( a 상태에서 + a 토큰을 받아 E를 연결하고, 이후 ) 토큰을 받아 최종 연결을 하는 것을 확인할 수 있다.
두 방법 중 뭐가 더 좋은 방법이라고 결정할 수는 없지만, Java에서 사용하는 필러라는 파서생성기는 Top-down, lex와 같은 파서생성기는 bottom-up 방식을 이용한다.
🌱 좌파스, 우파스
Top-down 방식은 좌측유도와 같은 순서의 생성규칙을 적용한다.
즉 Top-down 방식으로 생성된 생성규칙 번호 리스트는 좌측유도 중 적용된 생성규칙들의 리스트와 같으며, 이를 좌파스라고 부른다.
Bottom-up 방식은 입력 스트링의 왼쪽부터 매칭하기 때문에 우측유도의 역순과 같은 순서의 생성규칙을 적용한다.
즉 Bottom-up 방식으로 생성된 생성규칙 번호 리스트는 우측유도 중 적용된 생성규칙들의 리스트의 역순과 같으며, 이를 우파스라고 부른다.
좌파스를 이용하여 Top-down 방식으로 생성한 파스트리는 좌측유도의 유도트리와 같고,
우파스를 이용하여 Bottom-up 방식으로 생성한 파스트리는 우측유도의 유도트리와 같다.
즉, 좌파스, 우파스로 생성한 트리가 동일할 경우 이는 모호하지 않은 문법이라는 것을 증명한다.
예를 들어, 아래 문법을 이용하여 abac라는 스트링을 파싱해보자.