목차
📁 Disk Scheduling
디스크 스케줄링은 디스크라는 디바이스에 대한 스케줄링이다.
일반적으로 입출력 장치 스케줄링에는 선입선출 알고리즘을 사용하는데, 디스크의 경우에는 그렇지 않다.

먼저 디스크 장치의 구조를 보자.
디스크 뚜껑을 열면 사진처럼 금속판 한장 혹은 여러장이 있다.

위 사진은 금속판이 3장 있는 하드디스크이다.
이 금속판의 위, 아래 표면에 정보가 기록되는 것이다.
이 사진은 디스크 3장, 표면 6개가 된다.
디스크 한 면을 위에서 바라보면 왼쪽 그림처럼 둥근 띠 모양이 여러개 있는데, 이 띠 한줄 한줄을 트랙이라고 말한다.
바깥쪽부터 0번으로 시작하여 n-1번까지 번호를 붙인다.
하나의 면에는 보통 20개부터 1500개 정도의 트랙이 있다.
실린더란 모든 디스크에서 같은 번호의 트랙들의 집합이다.
즉 하나의 표면에 트랙이 100개 있으면 실린더도 100개가 있는 셈이다.
사진의 노란색 부분처럼 피자 조각 하나를 섹터라고 부른다.
섹터의 끝에 줄이 그어져 있는데, 실제 디스크에는 이런 줄은 없고, 각 섹터에 저장된 데이터들에 대해 패리티 값을 저장한, 논리적인 의미가 있는 부분이다.
이 패리티는 주기적으로 오류를 검사할 때 이용된다. 저장된 데이터에서 패리티 값을 새로 계산한 후에 이전에 저장한 줄 부분의 패리티 값과 비교하여 같으면 문제가 없는 것이다.
만약 다르다면 디스크 저장장치 오류 등 데이터가 의도치 않게 변경되었음을 말해준다.
섹터는 제조사가 정의한 물리적인 최소 정보 단위이고, 섹터 단위로 디스크에 가서 읽고 쓴다.
그러나 운영체제 입장에서는 디스크에 접근하는 정보 단위를 섹터가 아니라 4096바이트 크기의 블록이라는 것을 사용한다.
따라서 이 블록을 섹터로 매핑시켜주어야한다.
만약 블록과 섹터의 크기가 같다면 운영체제에서 하나의 블록을 읽거나 쓰려고 할때 디스크에서 하나의 섹터만 접근하면 된다.
만약 블록과 섹터의 크기가 다르다면, 보통 블록의 크기가 더 크므로 하나의 블록을 읽기 위해서 연속적인 섹터들 여러개를 같이 읽어와 운영체제에게 하나의 블록으로 전해준다.
위 오른쪽 그림을 보면 녹색이 디스크의 암이다.
암 끝에 헤드라는 것이 있다.
암 자체는 원통 디스크의 가장자리부터 안쪽까지 왔다갔다하고, 헤드가 디스크의 면 위를 스캔하면서 섹터에 저장된 데이터를 읽는 센서이다.
암이 바깥쪽 트랙에 있다고 하자.
노란색 부분을 읽으려면 암이 움직여야 할것이다. 그러면 디스크는 빙글빙글 돌 것이다.
암의 끝에 있는 헤드 밑에 노란색 부분이 오게 되면, 헤드가 센서로 스캔하여 정보를 읽는다.
운영체제는 디스크를 블록 단위로 접근한다.
운영체제는 디스크가 블록의 연속된 저장장소, 즉 1차원 배열로 간주한다.
위와 같은 디스크의 구조적 특징 때문에 디스크의 어떤 블록에 접근할 때 모두 같은 시간이 걸리는게 아니라 블록이 저장된 물리적인 위치에 따라 걸리는 시간이 다르다.
때문에 디스크 스케줄링이 필요하다.
먼저 디스크를 읽는데 걸리는 시간을 알아보자.
위 그림의 노란색 섹터에 들어있는 블록을 읽는다고 가정하면, 제일 먼저 암, 즉 암 끝의 헤드가 그 트랙으로 이동해야한다
이때 seak time이라는 시간은 암이 모터에 의해 원하는 트랙으로 오기까지의 시간이다.
이후 디스크가 빙글빙글 돌아서 암 끝의 헤드가 노란색 섹터부분으로 오는 시간을 rotational delay라고 한다.
seak time이 결국 디스크 성능을 좌우한다.
하드웨어적으로 고속 모터를 사용해서 암을 빨리 움직이게 할 수 있겠지만, 그러면 디스크의 가격이 비싸지고, 기계적인 움직임을 빠르게 만드는 것에도 한계가 있다.
그래서 소프트웨어적으로 개선하고자 하는 방법이 디스크 스케줄링이다.
📁 Disk Scheduling
First-In First-Out(FIFO)
디스크 스케줄링의 가장 기본적인 알고리즘은 First-in, First-out(FIFO), 즉 요청한 순서대로 처리하는 방법이다.

위 그림에서 y축은 트랙번호, x축은 시간의 흐름이다.
0번 트랙이 가장 바깥쪽, 199번 트랙이 가장 안쪽이라고 하자.
그림 위의 숫자들은 디스크에 접근 요청이 들어온 트랙 번호들을 순서대로 나열한 것이다.
그리고 현재 100번 트랙 위에 헤드가 있다고 가정되어 있다.
FIFO 방식의 예시는 다음과 같다.
먼저 프로세스에서 55번 트랙을 읽어달라고 요청하고 block 상태가 된다.
그러면 cpu는 다른 프로세스로 가는데, 이 프로세스에서는 58번 트랙의 어떤 블록을 읽어달라고 요청한다.
이런식으로 여러개의 요청이 올 수 있는데, 이 요청들을 디스크에 연결된 queue에 넣어놓는 것이다.
그러면 현재 위치가 100번 트랙이므로 그래프에서 점이 찍힌 곳으로 이동해야한다.
결과적으로 모든 요청들을 FIFO 방식으로 서비스하면 총 498개만큼의 트랙을 이동한다.
이 방법은 굉장히 비효율적이다.
Shortest Seek Time First(SSTF)
위 FIFO 방법에 대한 대안이다.
seak time이 가장 짧은 요청을 먼저 수행하라는 알고리즘이다.

위 방법으로 이동하면 총 248개의 트랙을 이동하므로 FIFO 방식의 반절정도로 시간을 줄일 수 있다.
하지만 SSTF 방법에도 문제점이 있는데, SSTF는 우선순위에 기반한 방법이다보니 우선순위가 낮은 요청은 오랫동안 기다리게 되어 starvation 현상이 생긴다는 점이다.
SCAN(Elevator Algorithm, Look Policy)

트랙 0번부터 안쪽에 있는 트랙까지 진행하면서, 진행방향 바로 앞에 있는 요청을 서비스하고, 안쪽으로 진행하고, 이후 더이상 요청이 없으면 다시 바깥쪽으로 이동하고, 요청을 서비스하는 방식이다.
안쪽 트랙으로 진행하면서 가장 안쪽에 있는 요청을 수행하고, 다시 바깥쪽으로 향하면서 가장 바깥쪽의 요청을 수행하고, 다시 방향을 바꾸는 방식으로 진행한다.
이 방식을 사용하면 총 250개의 트랙을 거친다.
SSTF 방법보다 이 예시에서는 조금 더 많았지만, 평균적으로 보면 성능이 비슷하다.
SSTF에서는 starvation 문제가 생기고, SCAN에서는 생기지 않기 때문에 요즘은 SCAN 방식을 사용한다.
📁 Disk Cache
다른말로 buffer cache, page cache라고도 한다.
디스크는 속도가 매우 느린 저장장치이기 때문에, 자주 접근하게 되면 시간이 많이 걸린다.
그래서 디스크를 접근할 때 걸리는 시간보다 더 빨리 접근할 수 있는 저장공간에 디스크의 사본을 가지고 있게 하는 방법이다.
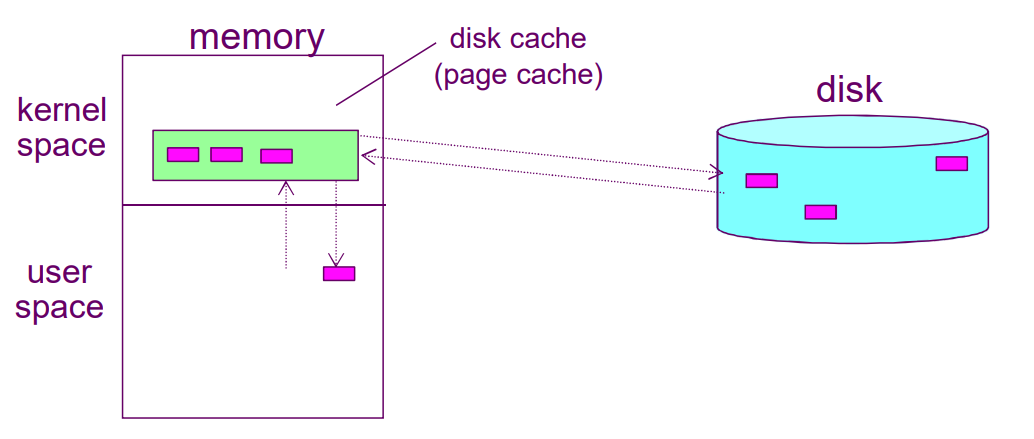
디스크보다 더 빠른 저장공간은 메인 메모리이므로, 운영체제가 메모리에 일부를 디스크 캐시에 할당하여 진행한다.
어떤 블록을 읽어달라고 프로세스가 요청하면, 해당 블록을 읽어와서 전달하면서 디스크 캐시라는 공간에 읽어온 내용의 사본을 저장한다.
이후에 같은 프로세스나 다른 프로세스가 같은 블록을 요청하면 운영체제가 디스크 캐시 안을 먼저 조사해서 해당하는 내용이 있다면 굳이 느린 디스크까지 가서 읽어올 필요 없이 메모리에 있는 내용을 바로 전달할 수 있다.
그래서 운영체제는 디스크 캐시에 가능한 한 많은 블록을 저장할 수 있도록 많은 메모리 공간을 할당하고 싶어하지만, 한계가 있기 때문에 일정 개수만큼 저장할 수 있다.
프로그램이 계속 실행되면 언젠가 디스크 캐시에 빈자리가 없어질 것이다.
이런 경우에는 하나를 지우고 새로운 것을 넣어야 할 것이다.
이때 어떤 블록을 없앨건지 결정하는 것을 Cache Replacement라고 한다.
Cache Replacement의 알고리즘으로 많이 쓰이는 것은 LRU와 LFU이다.
Least Recently Used(LRU)
시간을 기준으로 가장 오래전에 접근했던 것을 없애는 방법이다.
이 알고리즘을 구현하는 가장 직접적인 방법은 블록마다 시간 값을 저장하는 별도의 저장공간을 두고, 접근할때마다 시간을 기록하는 것이다.
그래서 시간 값을 비교하여 가장 오래된 것을 제거하면 되는데, 이 방법은 시간이 많이 걸리기 때문에 사용하지 않고,
stack이나 linked list 방법으로 구현한다.
linked list 방법으로 구현한다고 하면, 어떤 블록이 이용될 때 linked list의 가장 앞으로 옮기는 방식을 이용하여, linked list의 가장 뒤에 있는 것이 가장 오래된 것이므로 이것을 제거한다.
stack도 비슷한 방법으로 이용된 블록을 top으로 옮기고, bottom에 있는 것을 제거한다.
Least Frequently Used(LFU)
프로세스가 블록을 요청할 때마다 요청한 횟수를 기록한다.
이 횟수가 적은, 즉 자주 이용되지 않는 것을 쫓아내는 방법이다.


